Hyper-Pipelining Query Execution(下)
4. X100: A Vectorized Query Processor
上一篇翻译了 Hyper-Pipelining Query Execution 上半部分,核心思想就是 RDBMS 和 MonetDB 的优缺点。后半部分,就是如何从零开始设计新的查询处理引擎 X100。
新的 X100 查询处理引擎目标主要有三个:
- 高性能:以高 CPU 效率处理大数据量查询
- 拓展性:能够拓展到其他应用领域,比如 data-mining、multi-media retrieval等,并且能通过拓展代码在这些领域也能实现同样高的效率
- 伸缩性:能随着最低存储层次结构(比如磁盘)的大小进行伸缩
为了实现我们的目标,X100 必须与整个计算机架构中的瓶颈进行博弈:
Disk: X100 的 ColumnBM I/O 子系统面向高效的顺序数据访问。为降低对带宽的要求,它使用了垂直分段的数据布局(vertically fragmented data layout),在某些情况下,这种布局通过轻量级数据压缩得到了增强。
RAM: 与 I/O 类似,RAM 的访问路线是 memory-to-cache 和 cache-to-memory,其中可能会包含与硬件相关的优化,比如使用 SSE 指令预取(Prefetching)数据以及一些汇编指令来移动数据。
Cache: CPU Cache 是唯一与内存带宽无关的地方。
基于向量化处理(vectorized processing)模型,我们使用 Volcano-like execution pipeline。
本文把比较小(比如 1000个值)的能留在 CPU Cache 的数据块(chunk),叫 “vectors”,这也是 X100 查询执行的基本单位。X100查询处理算子都是 cache-conscious:因为会把巨大的数据集分割成 cache-chunk,只会在 cache 中进行随机访问。
CPU: 先让编译器生成 loop-pipelined 代码。为进一步提高 CPU 吞吐(主要是减少
mix指令中 LOAD/STOR 的次数),X100 也包含为整个表达式子树而不是单个函数编译向量化原语(vectorized primitives)的工具。目前,此编译是静态引导的,但它最终可能成为优化器强制执行的运行时活动(比如 LLVM JIT)。
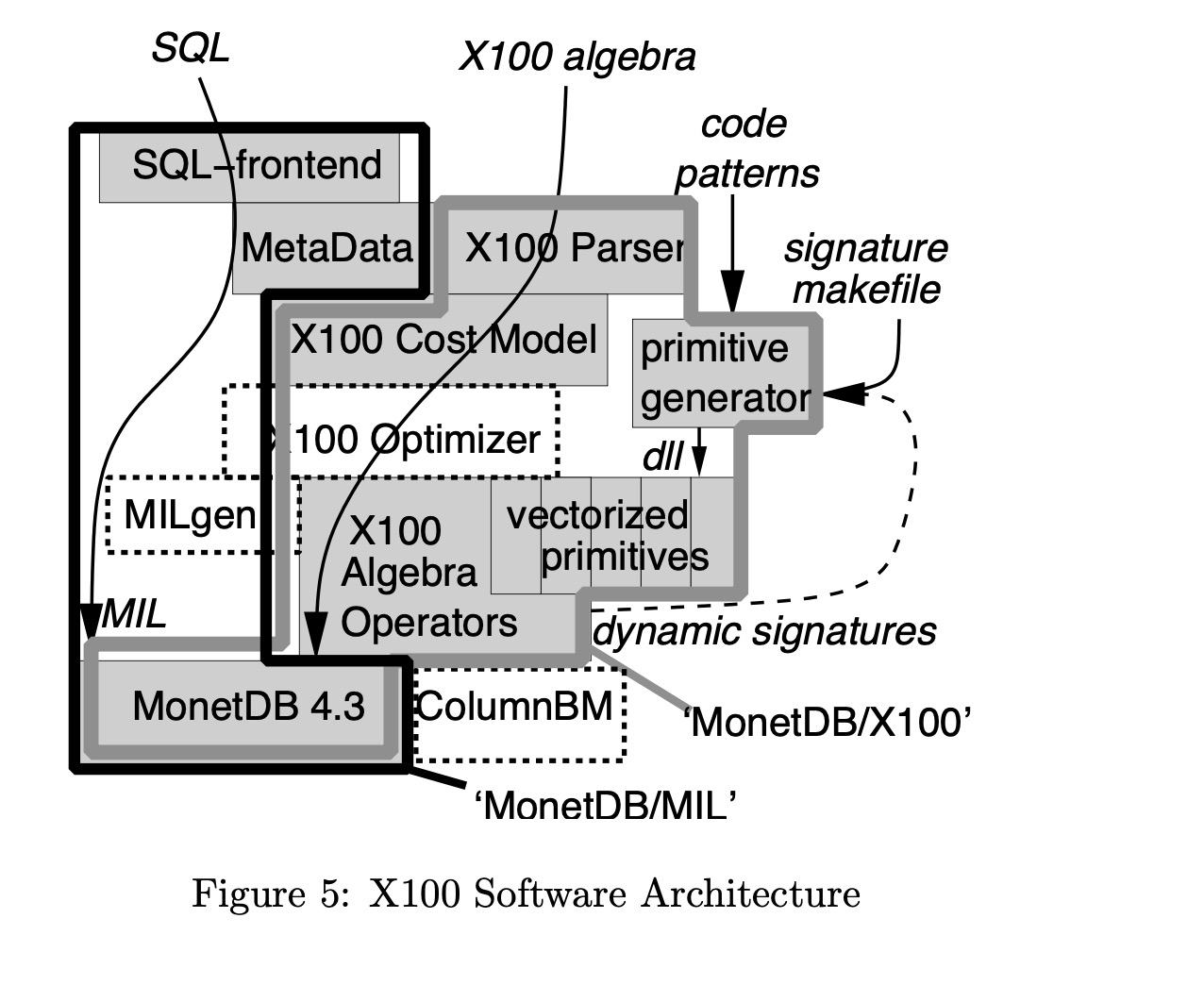
为了保持本文的重点,我们仅简要描述磁盘存储问题,也是因为 ColumnBM Buffer Manager 仍在开发中。 在我们所有的实验中,X100 使用 MonetDB 作为其存储管理器(如图-5 所示),它在 in-memory BATs 上运行。