Hyper-Pipelining Query Execution(上)
Abstract
在计算密集型(compute-intensive)的应用领域中,数据库系统在现代 CPU 上往往只能实现较低的 IPC(Instructions-Per-Cycle)效率。基于这一问题,本文的主要工作分为如下两个方面:
通过 TPCH benchmark,深入分析 IPC 效率不高的原因,即为什么每个周期(Cycle)执行的指令(Instructions)非常少。通过对不同的关系型数据库和 MonetDB[1] 进行分析,得到了一个设计查询处理器(Query Processor)的新指南。
本文的第二部分, 基于上述分析得到的查询处理器设计指南,如何为我们的 MonetDB 设计新的查询引擎 X100。
表面上, X100 类似于基于 Volcano 模型设计的引擎,关键区别在于 X100 所有的执行都是基于矢量处理 (vector processing)的概念,使得 X100 引擎的 CPU 效率非常高。
我们在 TPCH benchmark 输入数据为 100GB 的版本上评估了 MonetDB/X100 的性能,结果显示其原始执行能力(即未经过调优)比以前的技术实现高出一到两个数量级。
1. Introduction
现代 CPU 每秒可以执行大量计算,但前提是能够找到大量不存在依赖关系的任务,才利用其并行执行能力。在过去的十年里硬件飞速发展,这使得 CPU 以最大吞吐量运行(full throughput)和最小吞吐量(minimal throughput)运行时之间的速度差异可能存在着一个数量级。
那么大家就期望查询密集型工作负载(workload),比如 decision support, OLAP, data-mining 等,这些应用场景中都存在着大量不相关的计算,那么此时就应该让 Modern-CPUs 有机会发挥出接近最优的 IPC 效率。
然而研究却表名当前数据库在这些应用场景中,在 Modern-Cpus 上实现的 IPC 效率非常低。这就让人感到困惑。因此本文详细研究了在查询密集型应用场景中,关系数据库是如何与 Modern super-scalar(Hyper-Pipelined) CPUs 交互的,尤其是在 TPCH benchmark 场景中。
从该调查研究中我们得到的主要结论是:绝大多数 DBMSs 采用的架构阻碍了编译器使用最关键的性能优化技术(即 Pipeline),从而导致 CPU 效率低下。比如,在 Modern-CPUs 的流水线技术(Pipelined Prcoessing)架构下,非常火的 Volcano 模型的最通用实现,执行过程中数据传递方式是 tuple-at-a-time(即一次传输一个tuple),1)不仅会产生高额的解释开销(interpretation overhead),还会阻止编译器让 CPU 并行的机会。
除此之外,我们也分析了内存数据库 MonetDB 的性能,这是由本文作者团队使用 MIL 语言开发的数据库。MonetDB/MIL 的执行模型是 Column-at-a-time,因此不会有 tuple-at-a-time 执行模型中的解释开销问题(即被分摊了)。然而,它使用全列具体化(Full Column Materialization)的策略会导致在查询执行过程中产生大量数据。比如,我们就发现在 Decision Support 应用场景中,MonetDB/MIL 就被内存带宽严重限制,导致 CPU 效率急剧下降。
Materialization: 在这表达的语义是 “具体化”
因此,我们任务应该将 MonetDB 的 Coumn-at-a-time 执行流程和 Volcano 模型 Pipeline 实现中的增量具体化(Incremental Materialization)技术结合起来。我们从零为 MonetDB 设计并实现了一个新的查询处理引擎,即 X100,它使用的是向量化查询处理模型(vectorized query processing model)。
2. How CPUs Work
如图-1 显示了过去十年中每年最快的 CPU(按照 MHz 衡量 )、最高性能,以及当年最先进的芯片制造技术。
CPU MHz 提升的根本原因是芯片制造工艺规模的进步,通常每18个月缩小1.4倍(又称摩尔定律)。制造规模每缩小一倍,晶体管数量就会增加一倍(1.4 的平方),晶体管也会缩小一倍,布线距离和信号延迟也会缩小 1.4 倍。
因此,人们会期望 CPU MHz 随着反向信号(inverted singal)延迟的增加而增加,但是图1显示时钟速度已经进一步增加。
这句话不太理解,翻译不好:Thus one would expect CPU MHz to increase with inverted signal latencies, but Figure 1 shows that clock speed has increased even further.
这主要是由 Pipelining 技术完成的:将 CPU 指令的工作划分为多个阶段,减少每个阶段的工作量意味着可以提高 CPU 频率。1988 年的 Intel 80386 CPU 需要一个(或多个)周期才能执行一条指令,而 1993 年的 Pentium 已经有 5 级流水线,1999 年的 PentiumIII 增加到 14 级,而 2004 年的 Pentium4 有 31 级流水线。
但是 Pipeines 技术引入了两个风险: (1) 如果一条指令需要前一条指令的结果,则不能立即将其推入 pipeline,必须等到前一条指令(或其大部分)通过 pipeline,(即前一条指令执行完); 2) 在 IF-a-THEN-b-ELSE-c 条件分支代码中,CPU 必须要预测 a 的计算结果是 true or false。它可能预测为 false,并在 a 之后将 c 放入 pipeline 之中。经过许多阶段后,当 a 的计算结果出现了,CPU 可能确定自己前面猜错了(mispredicted the branch),那么就需要 Flush Pipeline(即丢弃 Pipeline 中所有待执行的指令),然后重新将分支 b 的指令填充到 pipeline 中。很明显,Pipeline 越长,被丢弃的指令就越多,性能惩罚也就越高。
对应到数据库系统,依赖于数据的分支是无法预测的(比如在选择性不是很高也不是很低的数据上进行分支预测),并且会显著降低查询执行速度。
此外,Super-scalar CPUs(又名 Hyper-Pipelined CPUs)提供了并行执行多条指令(前提是他们之间是不存在依赖关系)的可能性。也就说,CPU 不是只有一条,而是有多条 Pipelines。因此,在每个指令周期,新的指令可以被放入到每个 Pipeline 中,只要他们与所有正在的指令之间不存在依赖关系。因此,Super-scalar CPUs 的 IPC > 1。 图 1 显示了现实世界中 CPU 性能比 CPU 频率增长得更快,就是因为这个原因。
Modern-CPUs 总是会以不同的方式进行平衡。
- Intel Itanium2 具有多个并行 Pipelines 的 VLIW (Very Large Instruction Word)处理器,它只有非常少的 7-stage Pipeline,但是在一个指令周期内能执行多达 6 个指令,因此它的拥有一个相对低的时钟速度,为 1.5GHz。
- 相比之下,Intel Itanium4 拥有长达 31-stage Pipeline,拥有 3.6GHz 的时钟速度,但是一个指令周期却最多只能执行3个指令。
无论使用哪种方式,为了达到 CPU 理论上的最大吞吐量, Itanium2 在任何时刻都需要 7 * 6 = 42 个没有依赖关系的指令,而 Itanium4 却需要 31 * 3 = 93 个。由于不总是能找到满足最大吞吐量的条件,因此许多程序使用 Itanium2 的计算资源效果比 Itanium4 更好,这解释了为什么在 benchmark 中,尽管时钟速度差异很大,但两种 CPU 的性能表现却相似。
绝大多数编程语言并不会要求程序员在他们的代码中显式指定哪些指令(或者表达式)之间不存在依赖关系,因此。编译器优化(compiler optimizations)对于获得良好的 CPU 利用率就变得至关重要。其中最重要的技术就是 loop pipelining,一个由多个相互依赖的算子(F(), G())组成的算子从
$F(A[0])$, $G(A[0])$, $F(A[1])$, $G(A[1])$, …$F(A[N])$, $G(A[N])$
转化成
$F(A[0])$, $F(A[1])$, $F(A[2])$, …$F(A[N])$, $G(A[0])$, $G(A[1])$, $G(A[2])$, …$G(A[N])$
即将两两相互依赖的算子变成不依赖的
假设: F() 的 Pipeline 依赖延迟是 2 cycles,且当 G(A[0]) 送入 Pipeline 执行时,F(A[0]) 的执行结果已经可用。
在 Itanium2 处理器上,compiler optimizations 的重要性甚至更强:
- 因为编译器必须要在编译期找到可以进入不同 Pipelines 的指令,而其他 CPUs 可以通过乱序执行(Out-of-Order Execution)在运行完成这项任务。由于 Itanium2 不需要任何复杂的逻辑来查找 Out-of-Order Execution 的机会,因此它可以包含更多的 Pipelines 来完成实际工作。
- 此外,Itanium2 还有个叫做 branch predication 的特性,可以用于消除 branch mispredictions(允许并行执行 THEN 和 ELSE 两个分支,并在条件 a 的计算结果确定后,立即丢弃错误分支的执行结果)。而检测 branch predication 的机会也是编译器的任务。
图-2 展示了查询 SELECT oid FROM table WHERE col < X 的 mirco-benchmark,其中 X 是均匀随机分布在 [0, 100] 区间,并且我们从 0 到 100 变动着 X。
由于分支预测错误,像 AthlonMP 这样的普通 CPU 显示出大约 50% 的最坏情况行为。

通过采纳 [17] 中的建议,通过巧妙地重写代码,将分支预测转换为 boolean 计算(即predicated 的变体)。尽管这个重写后的代码与分支选择性无关了,但是却引入了更高的均摊成本(average cost)。然而有趣的是,在 Itanium2 处理器上,”branch” 版本却有着更高的效率,并且也和分支选择性无关,这是因为编译器将分支转化为硬件预测(hardware-predicated)代码。
最后,我们也应该提以下片上缓存(on-chip cache,即 L1, L2)对 CPU 吞吐量的重要性。CPU 执行的所有指令中大约 30% 会有内存加载(memory load)和写入内存(memory store)操作,即需要访问 DRAM 芯片中的数据,而这些 DRAM 芯片距离主板上的CPU有几英寸,这对内存延迟施加了大约 50ns 的物理下限,(即 CPU 访问 DRAM 中的数据至少有 50ns 的物理延迟)。在频率为 3.6G 的 Itanium4 CPUs 上,这个 50ns 的最小延迟(还是理想情况下)就会转化为 180个等待周期,因此只有当程序访问的内存绝大多数都已经缓存在 L1/L2 等高速缓存中时,Modern-CPUs 才有机会以其最大吞吐量运行。
最近的数据库研究表明,内存访问成本(cache misses)严重损害了 DBMS 的性能,并且如果使用缓存敏感型(cache-conscious)数据结构,比如 cache-aligned B-Trees,或者使用 column-wise 数据布局(比如 PAX 、MonetDB 中的 DSM),就可以显著改善数据库性能。此外,将随机内存访问模型(random memory access patterns)限制在某一个区域,使其适合 CPU 缓存,这样的查询处理算法(例如 radix-partitioned hash-join 算法)也是可以极大提高数据查询性能。
总的来说, Modern-CPUs 已经变成一个高度复杂的设备,处理器的指令吞吐量可能会相差几个数量级,这主要取决于一下四个因素:
- memory loads 和 memory stores 的 cache 命中率
- 分支的数量以及他们是否能被预测
- 编译器和 CPU 平均能检测到的不相关指令数量
研究表名,即便是在商业数据库中,查询执行引擎的 IPC 也才 0.7,也就是说每个指令周期执行的指令少于1个。相比之下,科学计算(例如矩阵乘法)或多媒体处理却可以从 Modern-CPUs 中获得的平均 IPC 高达 2。因此我们认为数据库不应该表现得这么糟糕,特别是在需要检查数百万 tuples 并计算表达式的大规模分析任务中。这些任务具有大量的独立性,应该能够完全填满 CPUs 所能提供的所有 Pipelines。因此,本文目标是调整数据库架构,尽可能将其暴露给编译器和 CPU,从而显着提高查询处理吞吐量。
3. Micro-benchmark: TPCH Q1
虽然我们总体上以查询处理的 CPU 效率为目标,但我们首先关注表达式计算(expression calculation),放弃更复杂的关系操作(比如 JOIN)以简化我们的分析。我们选择 TPCH benchmark Q1(如图-3所示)来进行分析,因为在我们测试的所有 RDBMSs 上,该 Query 都是CPU 密集型的(CPU-bound)。此外,这个Q1的执行计划非常简单,以至于几乎不需要优化和花哨的 JOIN 实现。因此,所有数据库都在一个公平的竞争环境中运行,并主要突出它们计算表达式的效率。

TPCH benchmark 运行在 1G 大小的数据仓库上,这个大小可以通过 Scaling Factor (SF) 来调节。Q1 是对大小为 SF * 6M tuples 的表 lineitem 进行 scan,几乎选择了该表的所有的数据(SF * 5.9M tuples),并计算了多个 fixed-point 十进制表达式:两个 column-to-const 减法,一个 column-to-const 加法,三个 column-to-column 乘法以及8个聚合计算(四个 SUM,三个 AVG和一个 COUNT)。聚合分组是针对两个单字符列(two single-character column),并仅产生四个唯一的组合,因此通过小的 hashtable 就能高效完成,不需要额外的 IO,甚至不需要 CPU 缓存命中。
下面,我们先分析Q1在关系型数据库上的性能,然后分析在 MonetDB/MIL 上的性能,最后是通过 hand-coded 实现的性能。
3.1 Q1 on Relational Database Systems
从 RDBMSs 早期开始,他们的查询执行功能就是通过实现物理关系代数(Physical Relational Algebra)来提供的,这通常遵循 Volcano 流水线处理模型。然而,关系代数的参数有很高的自由度。比如,即使是一个简单的 ScanSelect(R, b, P) 也只能在查询时(query-time)才能完全了解:
- 输入关系 R 的格式(列数、列类型和记录偏移量,
- 布尔选择表达式 b (可以是任何形式),以及
- 定义输出关系的 projection 表达式 P 的列表(每个表达式的复杂度都是任意的)
实际上,为了处理所有可能的 (R,b,P),DBMS 开发者必须实现一个可以处理任意复杂度表达式的表达式解释器(expression interpreter)。
这样一个 interpreter 的问题在于做有用功的成本(即执行 query 中出现的表达式)仅仅占整个查询执行成本(total query execution cost)的一小部分,尤其是当 interpretation 的粒度是 tuple 时更为严重。我们可以在表-2 中看到这种情况,该表显示了 SF=1 时,MySQL-4.1 执行 TPCH Q1 时的 gprof 记录。
- cum: 第一列是第二列的累加和
- excl: 第二列显示函数所消耗的时间占总执行时间百分比,不包括该函数调用其他函数所花费的时间。
- calls: 第三列显示该函数的调用次数
- 第四列和第五列显示每次调用函数的平均指令数,以及实现的 IPC

从表-2可得如下两个结论:
耗时组成: 完成所有“工作”(表-2中以粗体显示)的五个操作仅相当于总执行时间的 10%。另外 28% 的时间用于聚合操作中 HashTable 的创建和查询,还有剩余的 62% 的时间消耗在
rec_get_nth_field等函数上,用于将产生的结果复制给用户。而其他因素,比如锁的开销(pthread_mutex_unlock, mutex_test_and_set)或者 buffer page 的开销(buf_frame_align)似乎可以忽略不计。“Item” 操作的成本与查询的计算工作相呼应。比如,
Item_func_plus::val函数每次执行都消耗 38 个指令。这个性能记录是在配备了 MIPS R1200 CPU 的SGI机器上获得的,该机器可以在一个指令周期执行 3 个整数或浮点指令和一次 load/store,平均操作延迟约为 5 cycles。一个简单的 “+” 算法用 RISC 指令实如下:
1
2
3
4
5
6double plus(double src1, double src2) {
LOAD src1, reg1
LOAD src2, reg2
ADD reg1, reg2, reg3
STOR dst, reg3
}该代码中的限制因素是三个 LOAD/STOR 指令,因此 MIPS 处理器每 3 个周期才能可以执行一次加法操作。而 MYSQL 执行一次 Item_func_plus::val 所需的周期是是 #ins/IPC = 38/0.8 = 49 cycles。
对于如此高昂的成本,一个解释就是没有 loop pipelining,因此这个加法是由四个存在依赖关系的指令组成,必须彼此等待。由于指令平均延迟为 5 cycles,这就解释了大约 20cycles 的成本,49 cycles 中的剩余其他 cycels 则消耗在函数之间的跳转、函数的入栈出栈。
我觉得这解释有点牵强
MYSQL 以 “tuple-at-a-time” 策略执行表达式的结果有两点影响:
- Item_func_plus::val 只执行一次加法,阻碍了编译器创建 pipelined loop。因为一个操作(比如这里的一次加法操作)的指令是具有高度依赖的,必须生成空的 pipeline slot 来等待(甚至停顿等待)指令延迟,以至于 loop 的成本变成 20cycles 而不是 3cycles。
- 函数调用的成本(大约 20cycles)只能在一次操作中分摊,这使得该操作成本翻倍。
总而言之,tuple-at-a-time 即一次只针对一个数据进行操作,导致无法 pipelined loop + 无法分摊成本。
此外,我们也在知名的商业数据库上测试了相同的查询 Q1,如表-1 第一行所示。虽然我们没有该产品的源码,无法获得 gprof 性能记录,但是该 RDBMS 的查询评估成本和 MYSQL 是极其相似的。表-1的下半部分是从 TPC 网站获取的一些官方 TPCH Q1 结果。

3.2 Q1 on MonetDB/MIL
MonetDB/MIL 是由本论文作者团队开发的,因使用垂直分片(vertical fragmentation),按列存储表(storing tables column-wise)而知名。
我们使用 MonetDB/MIL SQL frontend 将 TPCH Q1 转化为 MIL 语言后再执行。表-3显示了 20个 MIL 调用情况,它们总共占用了 99% 以上的查询运行时间。基于 TPCH Q1,MonetDB/MIL 是明显快于 MYSQL 和同一机器上的商业 DBMS,并且和表-1中已公布的 TPCH 结果也具有竞争力。然而,仔细观察表-3会发现,几乎所有 MIL 操作都是内存密集型(Memory-bound)而不是CPU密集型操作(CPU-bound),即受限于内存而无法充分利用 CPU 资源。
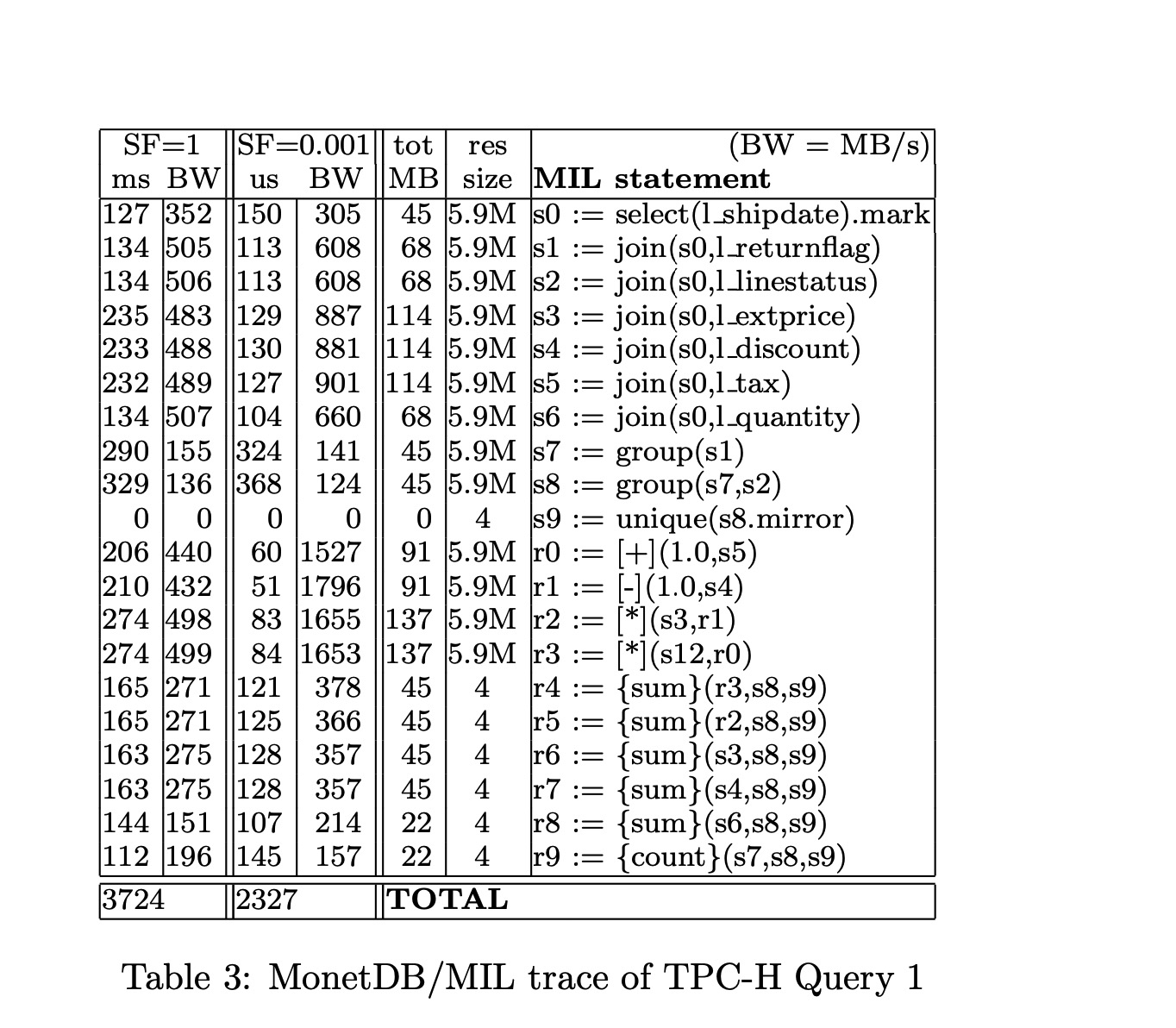
在将 TPCH 数据集的规模系数 $SF = 0.001$ 时,再运行相同的查询计划,表 lineitem 所有使用到的列和产生的中间结果(intermediate results)此时都都能填充到 CPU Cache 中,这就消除了CPU和内存之间的流量,然后,MonetDB/MIL 的速度几乎是原来的两倍。
表-3的第 2 列和第 4 列显示的是各个 MIL 操作实现的 bandwidth(BW,以 MB/s 为单位),同时计算了输入 BAT(Binary Association Table) 的大小和生成的输出 BAT。
- 在 SF=1 时,MonetDB 带宽上限卡在 500MB/s,这是在该硬件上可持续的最大带宽
- 在 SF=0.001 时,能够完全在 CPU 缓存中运行,此时带宽上限可以达到 1.5GB/s。
对于乘法 [*](),bandwidth 只有 500 MB/s 意味着 tuples 速度是 20M/s (16 个字节输入,8 个字节输出),因此在我们的 1533 MHz CPU 上每个乘法需要 75 cycles,这比 MySQL 还要拉胯。
因此,MonetDB/MIL 的 column-at-a-time 策略表现出两面性:
优点: MonetDB 不容易遇到 MySQL 的问题,即 90% 的查询执行时间都消耗在 “tuple-at-a-time” 模型的解释开销上。
这是因为乘法是操作整个 BATs (这是个数组,其 layout 在编译时就已知),那么编译器能够使用 loop-pipelining 技术,使得这些运算具有很高的 CPU 效率,具体体现在表-3 SF=0.001 的结果中。
缺点:Full Materialization
当基于大量 tuples 进行复杂逻辑表达式计算时,查询将为表达式中的每个函数 materialize 整个结果列。然而,这样的中间结果对于整个查询而言并不是必要的,它只是作为表达式中其他函数的输入。比如。在一个查询计划中,聚合操作是最顶层的算子(即执行计划的根节点),那么最终输出的结果大小甚至可以忽略不计(比如TPCH Q1)。在这种情况下,MIL 产生的中间数据远多于实际所需的,导致非常高的带宽消耗(即所需的带宽也远多于实际所需的)。
而这个问题在 Volcano-like 查询执行引擎中并不存在,它可以一次性完成选择、计算和聚合,而不具体化任何数据(即不会产生无用的中间数据)。
所以就是要结合 Volcano-like 和 MonetDB 各自的优点重新设计新的 X100。
3.3 Q1 Baseline Performance
为了获得现代硬件对 Q1 等问题的处理能力的 baseline,我们将其实现为 MonetDB 中的一个 UDF,如图 4 所示,该 UDF 仅在查询涉及的那些列中传递。

从 表-1 可以看出这个 UDF 实现(标记为“hand-code”)居然将查询成本降低到了 0.22s。 然而,表-1也可以看出,新的 X100 查询处理器(见下一篇博客)能够达到此 UDF 版本的 2 倍以内(也就是虽然慢了一倍,但还是算很快,毕竟编译器自动生成的肯定比不上大佬手写的)。