如图-1是 StarRocks Pipeline 的整体执行结构:
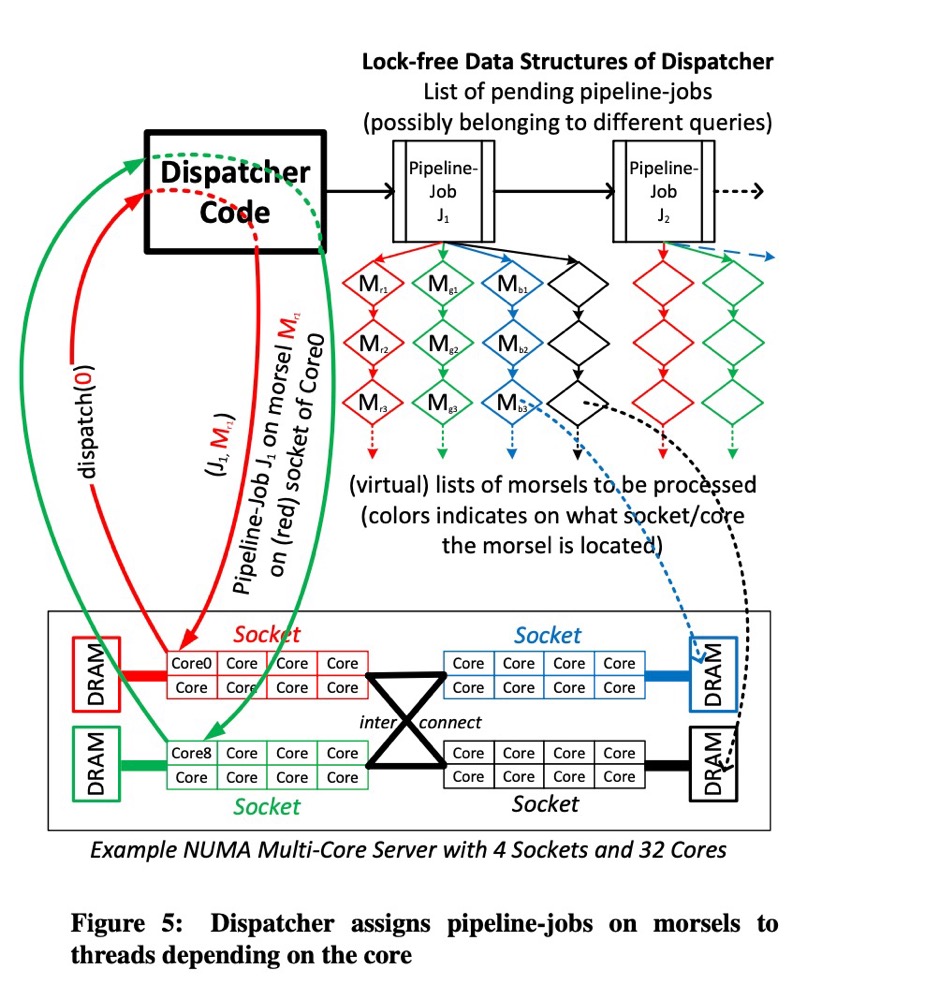
对比论文中 Morsel-Driven Parallelism[1] 第三节中的 figure-5 与 StarRocks Pipeline 实现中,概念映射关系大致如下:
QEPObject 即 PipelineDriverPoller,负责将前置依赖都已经 Ready 的 Pipeline 传递给 Dispatcher
Task 即 PipelineDriver,是可执行任务单元,由两部分组成:输入(Morsel) + 处理流(PipelineJob)。
Dispatcher 即 DriverQueue,是存储 PipelineDriver 的任务队列,可以根据优先级(Resource Group)或者 FIFO 方式任务分发
Morsel List 即 MorselQueue,根据优化器,自动选择不同的 MorselQueue
GlobalDriverExecutor 所有的任务都是在一组固定的线程池 GlobalDriverExecutor::_thread_pool 中执行。默认是使用当前CPU的核数 CpuInfo::num_cores(),也可以设置参数 config::pipeline_exec_thread_pool_thread_num 指定线程池数目。 在 GlobalDriverExecutor::initialize 函数中启动 _max_executor_threads 个线程,函数入口 是 GlobalDriverExecutor::work_thread。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 std::unique_ptr<ThreadPool> driver_executor_thread_pool; _max_executor_threads = CpuInfo::num_cores (); if (config::pipeline_exec_thread_pool_thread_num > 0 ) { _max_executor_threads = config::pipeline_exec_thread_pool_thread_num; } _max_executor_threads = std::max <int64_t >(1 , _max_executor_threads); RETURN_IF_ERROR (ThreadPoolBuilder ("pip_executor" ) .set_min_threads (0 ) .set_max_threads (_max_executor_threads) .set_max_queue_size (1000 ) .set_idle_timeout (MonoDelta::FromMilliseconds (2000 )) .build (&driver_executor_thread_pool)); _driver_executor = new pipeline::GlobalDriverExecutor ("pip_exe" , std::move (driver_executor_thread_pool), false ); _driver_executor->initialize (_max_executor_threads);
Morsel Morsel 是 PipelineDriver 的输入。StarRocks 中一个 Morsel 的结构如下:
顶层基类 Morsel 中的 _from_version 是为了实现 Query Cache,只需要从文件系统中增量读取 [_from_version, version] 部分的数据,而 [0, _from_version) 部分的数据就可以从 Lrucache 中读取,其中_version 存储在子类 ScanMorsel 中。
基类 ScanMorsel 更加具体化地存储了本次要读取的数据元信息 {_tablet_id, _version}。如果 Morsel 可以进一步在划分,根据划分方式派生了两个子类。
OlapScanNode::convert_scan_range_to_morsel_queue 如下代码,是将本次待查询的 scan_ranges 根据 Pipeline 并行度 pipeline_dop 转化为 OlapScanOperator 中待查询数据的元信息,即 Morsel对象。流程如下:
先将 scan_ranges 一一对应的方式转化为 ScanMorsel
如果不开启 tablet 内并行,则使用 FixedMorselQueue 数据结构来存储本次 query 待处理的数据源 Morsels
enable_tablet_internal_parallel 默认值是 true,是个 SessionVariable,用户在每次查询中都可以更改该值。即便该值为 true,也不一定真会进行子划分, 由 Morsel-Driven Parallelism[1] 论文可知,Morsel Size 不建议太小,否则会带因为多线程竞争导致性能惩罚。因此 _could_tablet_internal_parallel 函数会基于本次查询的数据量进行估计,判断是否真需要开启。
如果开启,则每个 Morsel Size 估计在 splitted_scan_rows 左右。
具体的划分方式由 _could_split_tablet_physically 函数来确定。
这个函数是在构建 Pipelines 的过程中:数据源划分好后,一个 MorselQueue 和一个 Pipeline 构成一个 PipelineDriver。一个完整的 Scan 任务被划分为 pipline_dop 个 OlapScanOperator 并行执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 StatusOr<pipeline::MorselQueuePtr> OlapScanNode::convert_scan_range_to_morsel_queue ( const std::vector<TScanRangeParams>& scan_ranges, int node_id, int32_t pipeline_dop, bool enable_tablet_internal_parallel, TTabletInternalParallelMode::type tablet_internal_parallel_mode, size_t num_total_scan_ranges) pipeline::Morsels morsels; for (const auto & scan_range : scan_ranges) { morsels.emplace_back (std::make_unique <pipeline::ScanMorsel>(node_id, scan_range)); } if (morsels.empty ()) { return std::make_unique <pipeline::FixedMorselQueue>(std::move (morsels)); } if (!enable_tablet_internal_parallel) { return std::make_unique <pipeline::FixedMorselQueue>(std::move (morsels)); } int64_t scan_dop; int64_t splitted_scan_rows; ASSIGN_OR_RETURN (auto could, _could_tablet_internal_parallel(scan_ranges, pipeline_dop, num_total_scan_ranges, tablet_internal_parallel_mode, &scan_dop, &splitted_scan_rows)); if (!could) { return std::make_unique <pipeline::FixedMorselQueue>(std::move (morsels)); } ASSIGN_OR_RETURN (bool ok, _could_split_tablet_physically(scan_ranges)); if (ok) { return std::make_unique <pipeline::PhysicalSplitMorselQueue>(std::move (morsels), scan_dop, splitted_scan_rows); } return std::make_unique <pipeline::LogicalSplitMorselQueue>(std::move (morsels), scan_dop, splitted_scan_rows); }
MorselQueueFactory MorselQueueFactory 的集成关系如下:
IndividualMorselQueueFactory 是针对每个 pipeline 都创建一个 MorselQueue。而 SharedMorselQueueFactory 即在多个 pipeline 之间共享一个 MorselQueue。
convert_scan_range_to_morsel_queue_factory 函数是为 Pipeline 创建数据源 MorselQueue。scan_ranges_per_driver_seq 参数是由 front-end(fe)优化器生成的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 StatusOr<pipeline::MorselQueueFactoryPtr> ScanNode::convert_scan_range_to_morsel_queue_factory ( const std::vector<TScanRangeParams>& global_scan_ranges, const std::map<int32_t , std::vector<TScanRangeParams>>& scan_ranges_per_driver_seq, int node_id, int pipeline_dop, bool enable_tablet_internal_parallel, TTabletInternalParallelMode::type tablet_internal_parallel_mode) if (scan_ranges_per_driver_seq.empty ()) { ASSIGN_OR_RETURN (auto morsel_queue, convert_scan_range_to_morsel_queue (global_scan_ranges, node_id, pipeline_dop, enable_tablet_internal_parallel, tablet_internal_parallel_mode, global_scan_ranges.size ())); int scan_dop = std::min <int >(std::max <int >(1 , morsel_queue->max_degree_of_parallelism ()), pipeline_dop); int io_parallelism = scan_dop * io_tasks_per_scan_operator (); if (scan_dop > 1 && dynamic_cast <pipeline::FixedMorselQueue*>(morsel_queue.get ()) && morsel_queue->num_original_morsels () <= io_parallelism) { auto morsel_queue_map = uniform_distribute_morsels (std::move (morsel_queue), scan_dop); return std::make_unique <pipeline::IndividualMorselQueueFactory>(std::move (morsel_queue_map), true ); } else { return std::make_unique <pipeline::SharedMorselQueueFactory>(std::move (morsel_queue), scan_dop); } } else { size_t num_total_scan_ranges = 0 ; for (const auto & [_, scan_ranges] : scan_ranges_per_driver_seq) { num_total_scan_ranges += scan_ranges.size (); } std::map<int , pipeline::MorselQueuePtr> queue_per_driver_seq; for (const auto & [dop, scan_ranges] : scan_ranges_per_driver_seq) { ASSIGN_OR_RETURN (auto queue, convert_scan_range_to_morsel_queue ( scan_ranges, node_id, pipeline_dop, enable_tablet_internal_parallel, tablet_internal_parallel_mode, num_total_scan_ranges)); queue_per_driver_seq.emplace (dop, std::move (queue)); } return std::make_unique <pipeline::IndividualMorselQueueFactory>(std::move (queue_per_driver_seq), false ); } }
MorselQueue MorselQueue 的继承体系如下。
DriverQueue DriverQueue 的继承派生关系如下:
QuerySharedDriverQueue 是由于多级反馈队列远离实现,没有指定资源组的 query 都会进行这个队列中。WorkGroupDriverQueue 是针对设置 {cpu, mem} 资源限制 的 query,都是在 GlobalDriverExecutor 中初始化。
在 StarRocks Be(backend) 中是同时存在两个 GlobalDriverExecutor 对象,不同之处是分别用于实例化 QuerySharedDriverQueue 和 WorkGroupDriverQueue。
1 2 3 4 5 6 7 8 GlobalDriverExecutor::GlobalDriverExecutor (std::string name, std::unique_ptr<ThreadPool> thread_pool, bool enable_resource_group) : Base (std::move (name)), _driver_queue(enable_resource_group ? std::unique_ptr <DriverQueue>(std::make_unique <WorkGroupDriverQueue>()) : std::make_unique <QuerySharedDriverQueue>()), _thread_pool(std::move (thread_pool)), _blocked_driver_poller(new PipelineDriverPoller (_driver_queue.get ())), _exec_state_reporter(new ExecStateReporter ()) { }
PipelineDriverPoller 轮询判断某个 blocked_pipeline_driver 前置依赖是否已经 ready,ready 则加入 _driver_queue。
PipelineDriver 执行单元,在每次执行前后会更新统计信息,Executor 会基于统计信息进行下一次调度。
StarRocks Pipeline 的设计还是挺复杂的,比 Morsel-Driven Parallelism[1] 论文做了很多的优化。后续再针对每个具体的数据结构进行分析。
Reference