Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework
ABSTRACT
随着现代计算机架构的演进,与并行查询执行引擎中两个问题产生了矛盾:
- 为了充分利用多核,所有的查询工作必须很快均匀地分布在数百个线程中才能实现良好的性能加速;
- 然而,由于现代 CPU out-of-order 的复杂性,即使有准确的数据统计,也很难将工作均匀分配
因此,现有的针对 Volcano 的 "Plan Driven" 的并行方法遇到了负载均衡问题(load balancing) 和 上下文切换 (context switch)瓶颈,无法随着CPU架构的升级进行伸缩。许多多核架构面临的第三个问题就是 Memory controller 的去中心化,进而引起 NUMA(Non-Uniform Memory Access)问题。
因此,本文提出了一种 "Morsel Driven" 查询引擎执行框架,调度变成了一个细粒度的 runtime 任务,且能利用 NUMA 特性。Morsel- Driven 查询处理引擎接受输入数据的一小片段(”morsels”),然后将 morsels 调度给 work 线程,这些 work 线程运行着完整的 operator pipeline,直到遇到下一个 pipeline 才会中断。
每个 work 线程运行着一个 pipeline,pipeline 中填充着不同的 operators 来操作数据。只要输入 morsels,就会依次从 SourceOperator 向 SinkOperator 流去。
并行度(degree of parallelism, dop)并不是个固定值,是可以在查询执行期间弹性地更改,因此 dispatcher 可以对不同 morsels 的执行速度作出反应,也可以动态地调整资源以响应工作负载中的新查询。此外。dispatcher 是能感知到 NUMA-local morsels 和算子状态(operator state)的数据局部性,以便绝大多数任务执行发生了 NUMA-Local 内存上。
1. INTRODUCTION
硬件都朝着提升多核性能的方向发展,本文使用术语 “many-cores” 来描述具有数十上百线程的CPU架构。与此同时,每台服务器的内存容量能增加到几TB,这也带动了内存数据库系统的发展。在这样的系统中,查询处理不再受 I/O 限制,并且可以真正利用多核的巨大并行计算资源。不幸的是,将 Memory Controller 转移至芯片中,以及将吞吐量拓展到几TB的巨大内存所需的内存访问分散化(decentralization of memory access)的趋势,产生的 NUMA。本质上,计算机本身已经成为一个网络,因为数据项的访问成本取决于数据和访问线程所在的芯片。因此,”many-cores” 并行化需要将 RAM 和cache 的层次结构纳入考虑范围,尤其要仔细考虑 RAM 的 NUMA 划分,以确保大部分线程在 NUMA-Local 数据上工作。
核心思想就是如何减少跨 core 通信:每个线程尽量访问自己核上的数据。RocksDB 中有个数据d结构 CoreLocalArray,给每个 core 分配一个对象,让线程访问数据时直接访问线程所在core,减少与 remote core 之间的跨核通信
在此之前的并发模型是 Volcano 模型,这种模型中 operators 是没有并行度可言的。因为并行的概念被封装成 Exchange Operator,这个算子在多线程间路由数据流,每个线程都执行着查询计划中完全相同的 pipelined 部分。这种设计就是 plan driven: 基于统计数据优化器在生成执行计划的编译期就确定需要启动多少线程,为每个线程实例化一个查询算子(query operator)并通过 exchange operators 实现这些 operators 间的通信。
本文提出 morsel driven 查询执行框架,如 fig-1 是执行三表 join 查询 $R \Join_A S \Join_B T$ 的示意图,并行性是通过并行处理不同 cores 上的每个pipeline 实现的。如图所示,有红色和蓝色两个 pipelines。
该框架的核心是调度机制(scheduling mechanism)即图中的 dispatcher,使得可以灵活地并行执行 operator pipleine,甚至可以在查询执行期间改变并行度。
一个 query 会划分成多个 segments,每个可执行的 segments 都会接受输入的一小部分(即 morsel)作为数据源,然后执行,直到遇到下一个 pipeline 才会输出具体的结果。
如 fig-1 中的红蓝所示,该 morsel 框架也支持 NUMA 局部处理:线程 T1 在一个 NUMA-Local 上输出输入,并且将其结果写入 NUMA-Local 存储区域,全程都没有跨 NUMA 结构。
fig-1 中的 dispatcher 运行着与机器相关的固定数量的线程,这样即便新的 queries 到来,也不会出现资源的过度消耗,并且这些工作线程与 cpu core 绑在一起,这样就不会因为操作系统将线程移动到其他CPU core 导致 NUMA 局部性失效。
一般工作线程数和 std::thread::hardware_concurrency() 函数返回值一致,而这个函数的返回值一般和机器有关。
morsel-driven 的调度机制核心特性是 task 的分配在 runtime 时完成的,并且完全弹性的,即可以通过增加或者降低正在执行的查询的并行度,来处理运行时变化的 workloads,这样就能实现完美的负载均衡(load balancing)。
morsel-driven 框架的思想从调度拓展到整个查询执行框架,即所有的物理查询算子都必须在他们所有的执行阶段都能实现 morsel 级别(morsel-wise)的并行,比如 HashJoin 的 build 和 probe 阶段。根据 Amdahl 定律,这对实现 many-core 可伸缩性至关重要。
morsel-wise 框架的一个重要特性就是能感知到数据局部性(data locality),这个起始于输入 morsels 和输出 buffer 的的局部性,并且拓展到 operator state 的局部性(operator state,一般是数据结构,比如 Aggregator 中的 HashTable)。尽管 operator state 是个可能被任何 cores 都访问到的共享数据结构,但是 operator state 确实仍有高度的 NUMA 局部性。
在为了实现 load balance 时,会需要从其他 core 获取一小部分 morsels,这时才会发生 remote NUMA 访问,即损失了 NUMA 局部性。
也就是说,通过主要访问 NUMA-Local 内存,可以优化内存延迟(memory latency),并将可能减慢其他线程速度的 cross-socket 内存流量降到最低。
本文,主要贡献是以下三点:
Morsel-driven query execution
这是一个新的查新计算框架,与传统的 Volcano 模型的不同点主要是使用 work-stealing 方式在线程间动态分配任务。这可以防止由于负载不均衡(load imbalance)导致CPU资源未被使用,并且可以实现弹性,即可以随时在不同查询之间重新分配 CPU 资源。
一些并行算法。见后文的 HashJon、Aggregate、Sort 并行算法
将 NUMA-Awareness 融入到数据库的方法
2. MORSEL-DRIVEN EXECUTION
使用 fig-1 中的 $\sigma(R) \Join \sigma(S) \Join \sigma(R)$ 来展示本文并行 pipeline 查询引擎的执行流程。假设 $R$ 是过滤之后最大的表,优化器将选择 $R$ 作为 HashJoin 的 probe 侧输入,而使用 $S$ 和 $T$ 来 build HashTable。
如fig-2左侧,根据 cost-based 优化器得到的查询计划由三条 pipelines 组成:
- 扫描、过滤表 T 后,构建 T 的 HashTable $HT(T)$
- 扫描、过滤表 S 后,构建 S 的 HashTable $HT(S)$
- 扫描、过滤表 R 后,再 probe $HT(S)$ 和 $HT(T)$,将结果存在输出区域

morsel-driven 框架中,代数计划的执行是由 QEPobject 来控制的,它会将可执行的 pipelines 传递给 dispatcher。因此,QEPobject 需要爱去检测数据的的前置依赖, 比如fig-2的例子中,只有在前两个 pipelines 执行完,3-rd pipeline 才能执行。在具体的每个 pipeline 中,QEPobject 会分配临时存储区(temporary storage areas),执行 pipeline 的并行线程会将结果写入到这个临时存储区。
在整个 pipeline 执行完后,临时存储区在逻辑上会被重新分割为同等大小的 morsels,这样后续的 pipeline 就可以从大小均等的新 morsels 上启动,而不是在 pipelines 之间保留 morsels 边界(容易导致数据倾斜)。任意时刻执行 pipelines 的线程数都受处理器硬件线程数量的限制,即上限是 std::thread::hardware_concurrency()。
为了写入 NUMUA-Local 并避免在输出中间结果时线程同步,QEPobject 为每个执行 pipeline 的 thread/core 分配一个存储区域。
$HT(T)$ pipeline 的并行处理如 fig-3 所示。
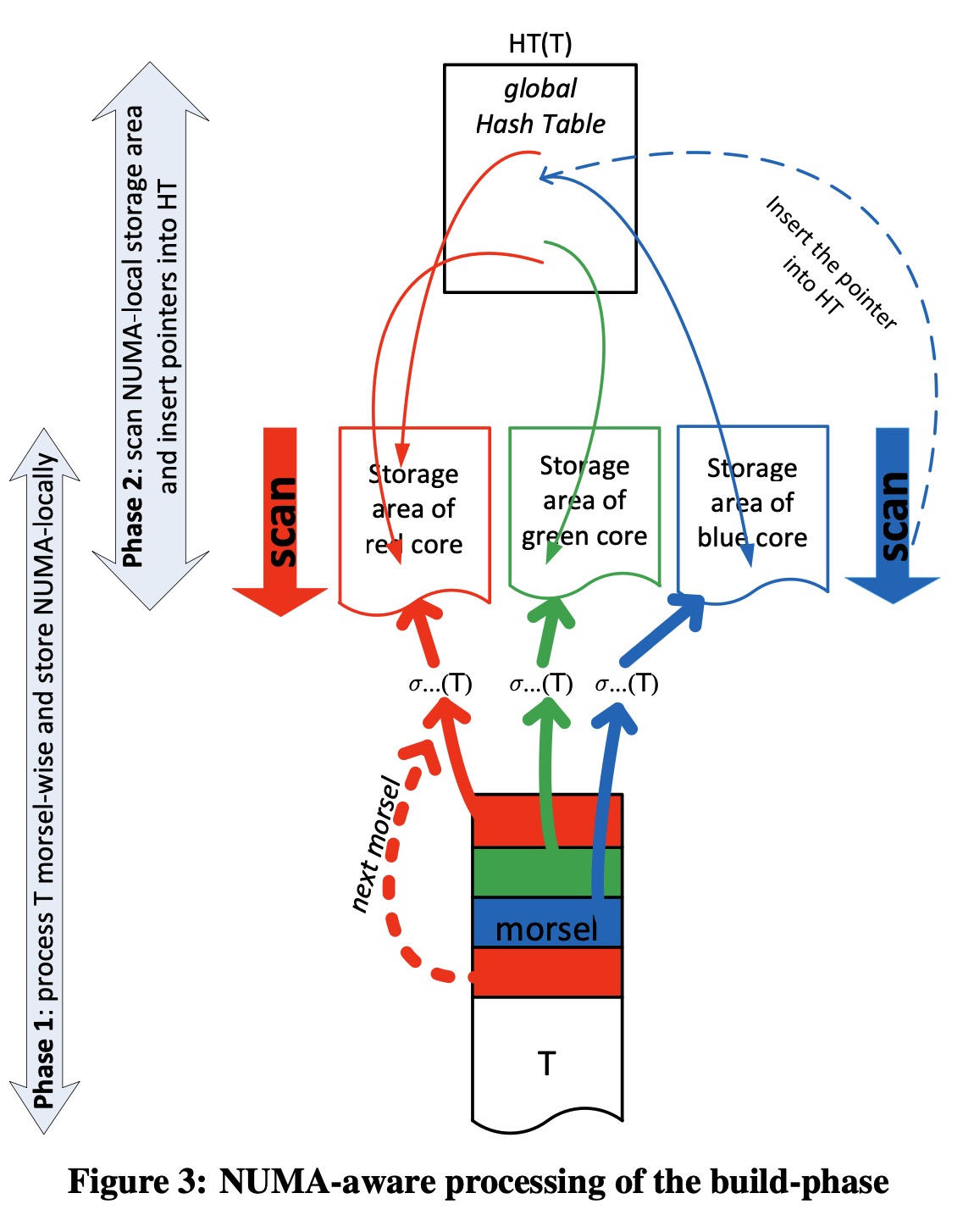
先重点关注第一阶段:每个线程先过滤输入 T,然后将过滤后得数据 tuples 存放在临时存储区。
在图中,有三个并行线程,每个线程一次操作一个 morsel。由于表 T 是以 morsel 为单位存储在多个 NUMA Node 的内存中,那么只要有可能(比如内存足够)那么 scheduler 就会将线程 T 所属的 NUMA Node 上的 morsel 分配给线程T。
比如在 fig-3 中颜色所表征的意思:在红色 Numa Node 上的 core 运行着红色线程,被赋予的任务就是处理红色 morsel。
只要线程 T 处理完了赋予的 morsel,要么被委托去执行其他任务(即work-steal 其他颜色的 morsels)或者获取同一个 Numa Node 上的 morsel(即相同颜色)来作为下一个任务。
fig-3 左侧标记了该 pipeline 被划分后的两个阶段。
在第一阶段,过滤后的数据直接写入了 NUMA-Local 存储区域,也就是说对于每个 core 都有个单独存储区域来避免线程同步。
为了保持后续处理阶段的的 NUMA 局部性,在同一个socket上本地分配特定 core 的存储区域。即该core的存储区域总是在一个 socket 上分配。
这里的 socket 是插槽。
当表 T 的所有 morsels 在第一阶段都已经处理完,在第二阶段会被位于相同 core 上的线程再次扫描,并且插入一个指向 $HT(T)$ 的指针。
之所以将构建 HashTable 分成两个阶段,是因为第一阶段完成后,数据的准确数据是已知的,就可以完美地确定全局 hashtable 的大小。这个大小确定的 gloabl hashtable 将会被系统中不同 NUMA Node 上的线程探测(probe)。因此,为避免竞争,这个 gloabl hashtable 就不应该位于特定的 NUMA 区域,而是应该分散在所有的 NUMA node上。由于许多线程都竞争着将输入插入 gloabl hashtable,那么必不可少地要实现一个 lock-free hashtable。
在 $HT(T)$ 和 $HT(S)$ 都构建完之后,probe pipeline 就可以被调度执行了。probe pipeline 的详细处理见 fig-4.

一个线程会向 dispatcher 请求任务,dispatcher 会在对应的 NUMA Node上 赋予该线程一个 morsel。也就是,如果线程位于红色 NUMA Node 上的 core,就会被分配表 R 在红色 NUMA Node 上的 morsel。Probe pipeline 的结果也会存储在 Numa 局部区域来保留后续处理阶段的局部性(这部分并没在图中画出)。
总得来说,morsel-driven 并行执行多个 pipelines 有点类似经典的 Volcano 模型实现,但是不同点在于 pipeline 是独立的,没有依赖的。也就是说,pipeline 共享数据结构并且 operators 能感知到并行执行的,因此最终必须执行线程同步(这一步需要通过有效的 lock-free 机制)。
未来可能的不同点,是执行 pipelines 的线程数也是完全弹性。也就是说,不仅在不同的 pipelines 之间的线程数不同,如 fig-2 所示,而且在查询执行期间,同一个 pipelien 内部也可能不同。
3. DISPATCHER
dispatcher 管控并将计算资源分配给并行的 pipelines。我们为每个机器提供的硬件线程(预)创建一个工作线程(work thread),并将每个工作线程永久地和他绑定在一起。
一个赋给 work thread 的 task 由两部分组成:pipeline job 和 pipeline job 的操作对象 morsel。由于 Task 的抢占发生在碎片边界,从而消除了可能代价高昂的中断机制。通过实验确定,morsel 大约在 100,000 个元组时,可以在即时弹性调整、负载平衡和低维护开销之间产生良好的权衡。
给指定 core 上运行的线程分配 Task 时,有三个主要目标:
- Locality: 保留 NUMA-Locality
- Full elasticity: 关于查询的并行度,具有完全的弹性
- Load balance: 要求所有参与 query pipeline 的核同时完成工作,防止先完成工作的 (fast)cores 等待其他的 (slow)cores。这个通过 worksteal 线程模型实现。
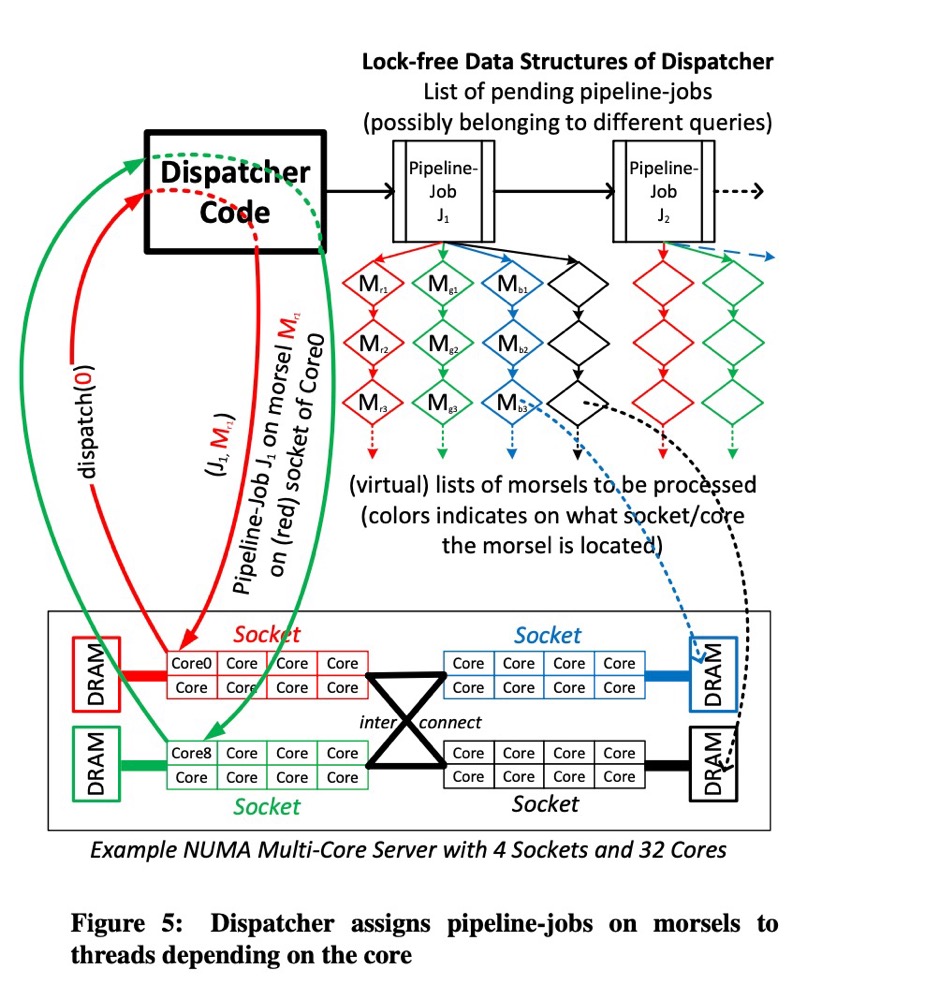
dispatcher 的架构如图 fig-5 所示,它维持了一个指向 pending pipeline jobs 的链表,这个链表中的 pipeline job 的前置依赖都已经处理完成。比如上面的 join 查询案例中,buidc pipeline job 会先插入到 pending jobs,只有在前两个 build pipelines 完成后,才会插入 proeb pipeline。正如前文所述,每个活跃的 queries 都是由 QEPobject 控制,它负责将可执行的 pipelines 传递给 dispatcher。 因此,dispatcher 只需要维护一个前置依赖都处理完成的 pipeline jobs 链表。
通常来说,dispatcher 的链表中包含的 pending pipeline jobs 是来自于并行执行的不同 queries,来适应 inter-query 的并行性。
3.1 Elasticity
通过 “morsel-at-a-time” 分发 pipeline jobs 来实现完全弹性并行性(fully elastic parallelism),允许根据服务质量模型智能调度这些查询间并行的 pipeline jobs。这样就能够在查询处理的任何阶段,优雅地降低长时间运行的查询Q1的并行度,以便优先考虑可能更重要的交互式查询Q2。一旦高优先级的 Q2 完成了,就会将时间片切给 Q2,这时候就可以给大多数甚至全部 cores 都分发 Q1 的 Tasks。会在 5.4 节展示弹性实验。
当前的实现中,所有的查询都是相同优先级,因此线程是均匀分发给当前所有查询,基于优先级的调度机制不在本文介绍之列。
对于每个 pipeline job,dispatcher 也为每个 pipeline job 维护了多个 moersls 链表,这是该 pipeline jobs 本次需要处理的数据源。对于每个 core,也存在一个单独的链表来实现局部性,比如对于 core0 上的任务请求一个 morsel,确保返回的 morsel 是来自于 core0 所在的 Numa Node 上。这两点可以从 fig-5 中的不同颜色看出。只要 core0 完成了分配的 morsel 及其 pipeline job 处理流程,就会请求一个新的任务,既可能来自于相同的 pipeline job,当然也可能不一定。这取决于正在执行的不同查询的不同 pipeline jobs 的优先级。比如,如果一个更高优先级的查询进入系统,那么就可能导致当前查询并行度降低。"Morsel-wise" 框架可以在不剧烈中断任务的情况下给不同的 pipeline jobs 重新分配不同的 cores。
3.2 Implementation Overview
出于说明目的,fig-5 中我们直接给每个 core 都分配了一长串 morsels,但是实际上,我们为每个 core/NUMA Node 都维护了一个存储区域并且按需将这个大的存储区域划分小的 morsels,即当 core 向 dispatcher 请求 Task 时。
此外,fig-5 中的 dispatcher 看起来像个独立运行的的线程,但是这会带来两个问题:
- dispatcher 本身需要一个 core 来运行,这可能会和执行 queries 的线程产生竞争;
- 因为 dispatcher 要分发任务,因此 dispatcher 本身可能会变成一个产生竞争的源泉(source of contention),成为性能热点,尤其当 morsels sized 被配置得特别小时
因此,dispatcher 仅被实现为一个数据结构,dispatcher 的代码被 work thread 自己来执行,即由 work-thread 自己从 dispatcher 中取出 Task,那么dispatcher 就很自然地和这个 work thread 在一个 core 上执行。
RocksDB 的 WriteThread 也是这个设计,WriteThread 本身就是 dispatcher 作用,并不会内部再启动一个线程来维护写入的 pending_writes。
因此,基于 lock-free 实现 pipeline jobs queue 和 morsels queue,即便同时有多个查询工作线程同时向 dispatcher 请求 Task,也能降低竞争。类似地,QEPobject 被实现为被动状态机,即通过观察 pipeline 数据之间的依赖关系来推动查询进度,比如在 probe hashtable 之前必须先之前 buid hashtable。只要一个 pipeline job 执行完了,QEPobject 就会被调用,因为某些 Task 无法向 dispatcher 申请到新的 morsel,需要判断该完成的 pipelin job 是不是其他 pipeline jobs 的前置依赖。而此状态机,是在最初向 dispatcher 请求 Task 的 work thread 的不再使用的 core 上执行的。
除了能在任意时刻将一个 core 赋值给不同 queries 的能力(即 Elasticit),该 morsel-wise 处理流程也能保证 load balance 和 skew resistance。如果一个 core 完成了自己 NUMA-Local 上的所有 Morsels,则 dispatcher 会将 NUMA-Remote 上的 Morsels 分配给他,即 WorkSteal。在有些 NUMA 系统中,不是所有 NUMA Node 都是直连的,因此应该优先从较近的 NUMA-Node 上的 steal。尽管在正常的环境下,从 NUMA-Remote steal work 发生的概率很低,但是仍有必要去避免线程处于空闲状态。由于总是将结果写入 NUMA-Local 的存储区域,因此在 WorkSteal 场景下,coreA 从 coreB 窃取任务,执行完结果还是写入 coreA 的 NUMA-Local 区域。
目前主要讨论了 pipeline 的内部并行实现,但是我们的并行机制也支持多个 pipelines 并行。比如上面的三表 join 案例中,由于 HT(S) 和 HS(T) 之间没有依赖关系,可以同时并发执行。但是这种形式的并行带来的收益是有限的:因为独立没有依赖的关系的 pipelines 的数量是远小于 CPU cores 的数量,并且每个 pipeline 中的工作量通常也不相同。此外,pipelines 间并行可能会因为破坏 cache locality 导致性能降低。因此,当前的实现中会避免一个查询中同时并发执行多个 pipelines。在本文的JOIN案例中,会先执行 pipeline T,T 执行完了再将 pipeline S 添加到 dispatcher 的 pending pipeline jobs 中。
除了 Elasticity,本文的 morsel-driven 查询处理框架也实现了简单而又优雅地查询取消功能(query canceling)。无论是因为用户中止了查询,还是因为OOM等系统故障,被取消的查询会在 dispatcher 中被标记 marker。只要该 query 的一个 morsel 处理完,就会去检测 marker,因此很快该查询的所有 work threads 都会停止。这个方式比让操作系统去 kill 所有线程更加合理,可以去执行每个 work threads 的 CleanUp 操作(比如,释放内存等)。
3.3 Morsel Size
与 Vectorwise 和 IBM’s BLU 数据库不同,这些数据库以 vector 为单位在 operators 间传递,本文数据库不会因为 morsel 无法填充到 cache 中带来性能惩罚。Morsels 是用于将大型任务分解为小的、大小恒定的工作单元(work unit),这样便于 work steal。因此,Morsel 大小对于性能来说并不是很关键,它只需要足够大以分摊调度开销,同时提供良好的响应时间。在第五章会通过实验来衡量 morsel size 对查询 select min(a) from R 性能的影响。因为这个query非常简单,因此会尽可能突显出 work-stealing 数据结构的重要性。
fig-6 显示,在开销可以忽略不计的情况下,Morsel 大小应设置为尽可能小的值,在本例中,设置高于 1000 的值即可。尽管最优的设置依赖于硬件,但是很容易通过试验的方式获得。
在多核系统中,共享的数据结构即便是通过 LOCK-FREE 的方式实现,最终也很可能会成为性能瓶颈。然而,在我们的 WorkSteal 数据结构中,有许多方面因素可以阻止这个问题。
在论文的实现中,完整的任务在最初就在所有的线程间完成分解,因此每个线程都临时拥有着一份 local range。由于我们将 cacheline 对齐到每个 range,因此在 cacheline 层不可能存在冲突。只有当 local range 处理完,尝试从另一个线程窃取 range 时才会发生冲突。
如果多个查询同时并发执行,对这个数据结构的压力则进一步减少。???
总是可以增加 morsel 的大小,来减少竞争
这就导致非常小的几率访问 work-stealing 数据结构。即便在最坏的情况,morsel size 非常大会造成无法充分利用线程资源,但是如果当前系统有足够多的查询,则也不会影响系统的吞吐量。
即一个查询虽然不会充分利用线程资源,多个查询一起就行了。
4. PARALLEL OPERATOR DETAILS
为了能够完整地并行每个 pipeline,pipeline 中的每个 operator 都需要满足:1)既能并行地读取 tuple;2)也需要能够并行地输出 tuple。在这一章,会讨论最重要的几个并行算子。
4.1 HashJoin
正如第二节 fig-3 中所示,HashJoin 的 HashTable 的构建由两个阶段组成。
OuterJoin 是上述算法的小变动: 在每个 tuple 中,会额外分配一个 marker 来表征这个 tuple 是否已经有匹配了。来 probe 阶段如果有相匹配的就会设置该 marker,因此在设置该 marker 之前,先检查下该 marker 是否尚未被设置,有利于减少不必要的竞争。Semi/Anti Joins 实现也是类似。
尽管 Balkesen 等[1]使用了大量的 single-operator benchmark 来表明一个高度优化的 radix-join 比 single-table join 达到个更高的性能。但是相比 radix-join,本文的 single-table join 具有以下特点:
- 对于较大的输入表,single-table join 是可以完全 pipelined,因此可以使用更少的空间(因为可以就地处理 probe input)
- 是个 “good team player”
- 可以从倾斜的key分布中获益
- 对 tuple size 不敏感
- 没有硬件相关的参数
由于上述实践中的优点,single-table join 在复杂查询中是要优于 radix-join。
radix-join 可以参考我的另一篇博客: JOIN 分区算法:Radix-Cluster Algorithm。但是我不太明白这里 single-table join 的含义,论文提及的几篇 HashJoin 论文都是 15721 中的论文,后续会再阅读一次,也可能会继续翻译,来加深理解。
4.2 Lock-Free Tagged Hash Table
本文 HashJoin 使用的 HashTable 有个优化:提前过滤(early-filter)。核心思想就是使用一个小的filter来标记 HashTable 的 bucket list(一个 bucket 实现为一个list),该 list 的所有元素都被 hash 来设置其中 1 bit。
如 fig-7 所示的插入过程,带插入的元素 entry->hash 基于某个算法预计算好,在 insert 函数中,需要基于 entry->hash 计算 entry 所属的 slot/bucket。
并采用头插法,将 entry->next = removeTag(old),其中 old 是 slot 当前的头节点,removeTag(old) 才是当前 head 节点真正地址。
完成上述操作后,就需要给当前首节点加上 Tag 信息:
- old & TagMask 需要取出当前已有的 Tag 信息,其中 TagMask 即 0xFF000000
- 计算新节点的 Tag 信息: tag(entry->hash)
- 将所有的的 Tag 信息存在 entry 的前 16bit 中
结合起来,就是 fig-7 中第9行的计算公式。再通过 CAS 操作将 new 插入到 HashTable[slot] 中。

这样就相当于首节点中使用 16 bit 就实现了一个微型 BloomFilter,可以在 O(1) 探测出来 unmatched 情况。相比较单独实现一个 BloomFilter 开销小很多,比如:
- 没有带来多余的内存访问,而单独的 BloomFilter 会引入额外的内存访问,甚至多次 IO;
- 对于大表,一个单独的 BloomFilter 数据结构难以填充到 CPU Cache;
- 不依赖优化器决策,是否需要走 BloomFilter 索引;
- 除了 join,这对于聚合场景也是有效的
实现中,我们对 HashTable 和 tuple 的存储区都使用 2MB 的 virtual memory page,这样的好处点:
降低了 TLB miss 的次数,page table 能保证填入到 L1 Cache,在 build 阶段产生的太多 kernel page 中断导致的拓展性问题也可以避免;
此外,我们使用 mmap 为 HashTable 分配内存。因为现代操作系统并不会立即分配内存,而是在第一次某个page有数据写入时才会触发。这样的好处是:1)不需要额外再添加一个阶段手动将 HashTable 内存初始化为 0;2)其次,HashTable 会自适应分布在 NUMA Node 上,因为这些 page 位于的 Numa Node,与首次写入该 page 的线程处在相同的 NUMA Node 上。
如果所有线程并发构建 HashTable,则会伪随机地分布在所有 Numa Node 上。如果只有来自单个 NUMA Node 上线程构建 HashTable,则该表就位于一个 Numa Node 上 – 这就是预期的情况。
说实在的,我感觉这篇论文夸大了 Lock-Free 的作用,似乎在这篇论文中是神器,但是 Lock-Free 也是有适用场景的。
4.3 NUMA-Aware Table Partitioning
为了实现 NUMA-Local Table Scan,表必须在所有的 Memory Nodes 上。最直接的方式即 round-robin。更好的方式是使用一些重要属性列的 Hash 值来对表进行分区。这样的好处是,如果JOIN的两个表都以 join-key 进行分区,那么匹配的 tuples 就通常位于同一个 NUMA Node 上。尽管 work-stealing 和 load imbalance 还是可能导致 remote-Numa 内存访问,但是大多数参与 JOIN 的pair 还是来自于同一个 NUMA Node。
比如,经典的 TPCH benchmakr 中,orders 和 lineitem 两个表都是按照 orderkey 进行分区,那么这两个表在基于 orderkey 进行 join 时,就能有很好的优化。
比如 Doris/StarRocks 针对这种情况,就提了个 Colocate Join 优化,他们在 TPCH 测试中这两个表的建表 SQL 如下:
1 | CREATE TABLE lineitem ( |