HTAP Overview: TiKV、TiFlash RAFT 同步流程
KvService
当用户从 mysql 客户端 insert 数据时,在 TiDB 通过 pd 定位到具体的每条数据对应的 region,然后将这个数据插入到对应的 region leader 中。TiKV 在接受到写指令后,再进行处理。本节专注于写流程本身,忽略 Tansactions 和 MVCC。TiKV 写指令的逻辑大致如下:

- RaftStoreRouter: KvService 封装了所有 TiKV 相关的 RPC 接口,在接受到写指令后,通过 RaftStoreRouter 将接收到的消息传递给后台线程池 BatchSystem 处理,在 RaftStore 内部再基于 Raft Log 的共识算法复制到其他 TiKV Followers。
- Transport:内部封装了 Raft Client,用于将 TiKV 的消息发送出去,比如 leader 和 follower之间的信息交互即基于 Transport 完成的。
Service
代码位于 src/server/service/kv.rs, 表征 TikvService,实现 tikvpb.proto 中的 TiKV RPC Service。
1 | pub struct Service<T: RaftStoreRouter<E::Local> + 'static, E: Engine, L: LockManager, F: KvFormat> { |
在这个字段中 storage 字段比较重要,其实例化后是 ServerRaftStoreRouter,
ServerRaftStoreRouter
RaftStoreRouter: 负责将 received 的 Raft 消息转发给 raftstore 中对应的 Region,ServerRaftStoreRouter 则是 trait RaftStoreRouter 的实例化。
1 | /// A router that routes messages to the raftstore |
收到的请求如果是一个只读的请求,则会由 local_reader 处理;其它情况则是交给内层的 router 来处理。
- router: 由 EK, ER
- local_reader:
Server
Server 表征的是一个服务器,Service 表征的是提供的服务。
位于 src/server/server.rs 文件中的 Server 是我们本次介绍的 Service 层的主体。它封装了 TiKV 在网络上提供的服务和 Raft group 成员之间相互通信的逻辑。Server本身的代码比较简短,大部分代码都被分离到 RaftClient,Transport,SnapRunner 和几个 gRPC service 中。
1 | pub struct Server<T: RaftStoreRouter<E::Local> + 'static, S: StoreAddrResolver + 'static, E: Engine> |
ServerTransport
ServerTransport 则是 TiKV 实际运行时使用的 Transport 实现(Transporttrait 的定义在 raftstore 中),其内部包含一个 RaftClient 用于进行 RPC 通信。
1 | pub struct ServerTransport<T, S, E> |
发送消息时:
- ServerTransport 通过上面说到的 Resolver 将消息中的 store_id 解析为地址,并将解析的结果存入 raft_client.addrs 中;下次向同一个 store 发送消息时便不再需要再次解析。
- 再通过 RaftClient 进行 RPC 请求,将消息发送出去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16impl<T, S, E> Transport for ServerTransport<T, S, E>
where
T: RaftStoreRouter<E> + Unpin + 'static,
S: StoreAddrResolver + Unpin + 'static,
E: KvEngine,
{
fn send(&mut self, msg: RaftMessage) -> RaftStoreResult<()> {
match self.raft_client.send(msg) {
Ok(()) => Ok(()),
Err(reason) => Err(raftstore::Error::Transport(reason)),
}
}
}
// TODO RaftClient::send 方法
Node
Node 位于 src/server/node.rs, 可以认为是将 raftstore 的复杂的创建、启动和停止逻辑进行封装的一层,其内部的 RaftBatchSystem 便是 raftstore 的核心。在启动 函数 Node:: start中,如果该节点是一个新建的节点,那么会进行 bootstrap 的过程,包括分配 store_id、分配第一个 Region 等操作。
1 | /// A wrapper for the raftstore which runs Multi-Raft. |
Node 并没有直接包含在 Server 之内,但是运行 raftstore 需要 Transport 向其它 TiKV 发送消息,而 Transport 包含在 Server 内。
所以我们可以看到,在 components/server/src/server.rs 文件的 init_servers 中(被 tikv-server 的 main 函数调用),启动过程中需要先创建 Server,然后创建并启动 Node 并把 Server 所创建的 Transport 传给 Node,最后再启动 Node。
1 | fn TiKVServer::init_servers<F: KvFormat>(&mut self) -> Arc<VersionTrack<ServerConfig>> { |
TiKV 包含多个服务,其中比较重要的是 TiKVService.
Raft log replication
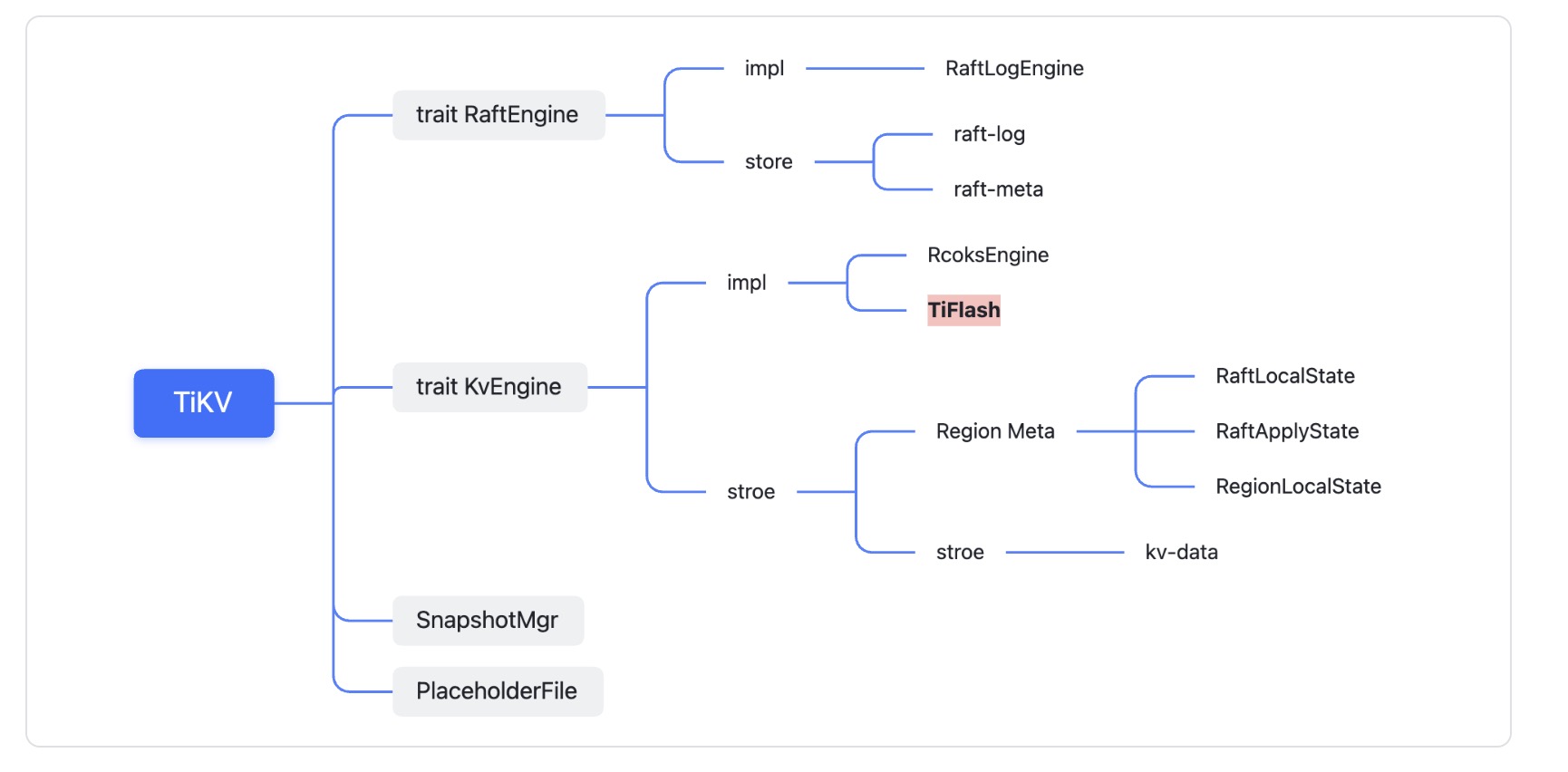
在 TiKV 内部有两个 rocksdb 实例:
- raft-rocksdb:用于保存新增的 Raft Log 及最新的 Raft state;
- kv-rocksdb:用于保存TiKV 执行 command 之后产生的 kv 数据
kv-rocksdb 中有四个 Column Family:- CF_DEFAULT:用于保存 MVCC 数据,(user_key, start_ts) => value
- CF_WRITE :用于保存 Value 可见的版本控制,(key, commit_ts)=> write_info
- CF_LOCK:用于保存事务的锁信息,表示有事务正在写这个 key,key => lock_info
- CF_RAFT:用于保存 Raft Log 中 applied 的最新元信息 RaftLocalState、RaftApplyState
自然,TiFlash 没有 ColumnFamily,就需要通过别的方式保存这些数据。
写入数据,从生成 Raft Log 到被存储到 kv-rocksdb 的整个流程如下:

在 Raft Replication 过程中,snapshot 是由 Raft 状态机自动产生的,比如当 follower / learner 出现宕机或者网络分区、新加入 follower / learner 节点或者处于 backup 需求,leader 就需要生成 snapshot。
follower、learner 接收到 snapshot 时,处理的优先级最高,因为这个 snapshot 是 follower 处理后续的 proposals 的基准数据。
BatchSystem
Batch System 类似线程池,是 RaftStore 的核心执行组件, 其职责就是检测哪些状态机需要驱动,然后调用 PollHandler 去消费消息。消费消息会产生副作用,而这些副作用或要落盘,或要网络交互。PollHandler 在一个批次中可以处理多个 normal 状态机。
PollHandler
PollHandler 负责处理处理接收到的消息,消息的处理流程按照如下trait。
1 | pub trait PollHandler<N, C>: Send + 'static { |

在 raftstore 里,一共有两个 Batch System。分别是 RaftBatchSystem 和 ApplyBatchSystem,对应的 PollHandler也分为 RaftPoller、ApplyPoller。
- RaftBatchSystem 用于驱动 Raft 状态机,包括日志的分发、落盘、状态跃迁等,当日志 committed 并持久化到 raft-rocksdb 后,会发往 ApplyBatchSystem 进行处理;
- ApplyBatchSystem 将日志解析并应用到状态机,数据持久化到 kv-rocksdb,执行回调函数回复客户端。
所有的写操作都遵循着这个流程,简要流程如下:

TiFlash
Overview
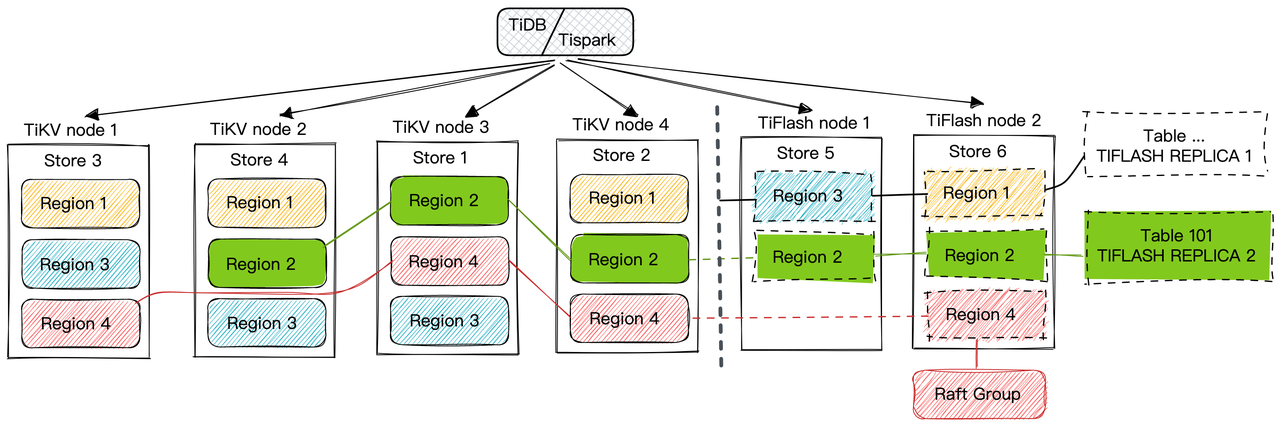
Arch
TiKV 是用 Rust 实现的,而 TiFlash 是用 C++ 实现的,TiFlash 和 TiFlash-Proxy(简称 Proxy)经常需要相互调用,这一机制基于 FFI (Foreign Function Interface)实现。
C++ 端和 Rust 端共享一个 ProxyFFI.h,任何新增的 FFI 调用只需要在该接口中定义一遍,调用 gen-proxy-ffi 模块即可生成 Rust 端的接口代码
TiFlash 和 TiFlash-Proxy 会各自将 FFI 函数封装入 Helper 对象中,然后再互相持有对方的 Helper 指针。
- RaftStoreProxyFFIHelper:是 Proxy 给 TiFlash 调用的句柄,它封装了 RaftStoreProxy 对象。TiFlash 通过该句柄可以进行 ReadIndex、解析 SST、获取 Region 相关信息以及 Encryption 等相关工作;
- EngineStoreServerHelper 是 TiFlash 给 Proxy 调用的句柄,Proxy 通过该句柄可以向 TiFlash 写入数据和 Snapshot、获取 TiFlash 的各种状态等

write path
TiFlash-Proxy 处理的是写流程,将TiFlash包装成TiKV,是将 TiKV 的 apply 流程中的 kv-rocksdb 替换为 TiFlash,由 TiFlash 来持久化保存kv数据。
TiFlash-Proxy 处理的写入主要分为普通的 KV write、Admin Command 以及 IngestSST。这些写入会被存放在内存中。
一个 region 的数据分为两个部分:
- committed:已写入列式引擎 storage,通过 tryFlushRegionCacheInStorage 函数来刷盘;
- uncommitted:尚未写入 storage 中的,由 RegionPersister 调用 persistRegion 函数持久化到 PageStorage中
所以一般 flush 的整体流程:
- tryFlushRegion 将 committed 的数据写入 storage 的 cache
- tryFlushRegionCacheInStorage 将 storage 的 cache 数据刷盘
- 将 uncommitted 的数据写入 PageStorage
流程图如下:
read path
读取操作,直接由 TiDB 通过 RPC 发送到 TiFlash 进行读取,不经过 TiFlash-Proxy。
Question
为什么说是 TiKV 是异步同步数据到 TiFlash 而不会影响 TiKV写入流程?
因为 TiFlash 作为 raft-learner ,非 voter ,即不具有投票权,leader 同步的 proposals,只需要原来 TiKV 集群的半数节点回应即可 commit,不需要等待 TiFlash 的回应,因此即便 TiFlash 节点出现问题,也不会拖慢原有TiKV集群。TiDB 是强一致性的,如果 TiKV 同步到 TiFlash 的流程比较慢,那么 TiFlash 是如何保证读取一致性的?
默认的 TiKV 是只有 leader 能提供读写能力,开启 Follower Read 后就能让 TiKV 集群中的 follower 节点也能分摊 leader 的读压力,Follower Read 的一致性是基于 ReadIndex 保证的- 先读取当前 Leader 的最新 commit_index,然后
- 等待 follower 自己的状态机的 applied_index >= commit_index
StaleRead
这两步,即可满足线性一致性。
1 | fn ready_to_handle_unsafe_replica_read(&self, read_index: u64) -> bool { |
TiFlash 可以视为特殊的 TiKV,对于 TiFlash 的读一致性保证基于 Learner Read 实现,原理与 TiKV follower 类似。
1 | bool RegionMeta::doCheckIndex(UInt64 index) const { |