tidb: 2PC transaction 写入 tikv 详解
ExecuteStmt
ExecuteStmt 是执行一条 Stmt 的大致流程。
EnterNewTxn
是用来准备事务相关的信息

RunInNewTxn

tikvStore::Begin
在 tikvStroe 内部结构如下:

KVStroe::Begin
每个 client connection 对应着一个 session, 事务相关数据的放在了session中, 它包含了对 kv.Storage 和 KVTxn 接口的引用。
kv.Storage接口定义了 Begin/BeginWithOption 接口,用来创建开始一个事务,主要实现者为KVStore。
KVStore::Begin 开始一个事务,如果此时 start_ts为nil,则会从PD 获取一个时间戳start_ts,并且作为事务的唯一标识txn_id,会由 KVSnapshot 对象保存事务开始的快照信息,方便后续和 TiKV 进行交互。其中 KVStore::Begin 内部的关系如下:

Begin之后,就基于Begin中创建的 snapshot 元数据信息从 TiKV 获取 snapshot,并基于该 snapshot 执行用户的 DML 操作,在 tikvTxn::Commit 之后开始将DDL的结果 mutations 使用 2PC 算法提交到 TiKV。
DML
DML 操作都是基于 Next 执行框架完成,即在 Next 函数完成执行。 比如 InsertExec::Next 函数中完成将插入的数据封装成{key, value} 写入到 KVTxn的 MemDB 中。等到 Commit 时从 MemDB 中取出写入的数据,再进入 2PC 阶段向 TiKV 提交数据。
增删改的流程如下,在 Next 的执行框架中完成操作最终都是调用 Table 的 xxxRecord 接口,操作的结果缓存在 KVTxn.KVUnionStore.MemDB 中。

1 | var ( |
COMMIT
twoPhaseCommitter
- 在 Commit 之前,数据会缓存在 KVUnionStore.MemDB 中
- 当执行用户的 COMMIT 时,在 KVTxn::Commit 函数中创建 twpPhaseCommitter,并调用 twoPhaseCommitter.initKeysAndMutations 函数遍历 KVUnionStore.MemDB 来初始化 memBuffMutations,作为后续的和 TiKV 交互的基础
- 在twoPhaseCommitter::execute 函数中,主要有五种操作:prewriteMutations、commitMutations、pessimisticLockMutations、pessimisticRollbackMutations 和 cleanupMutations。
他们输入都是 memBuffMutations ,然后都对 memBuffMutations 按照如下流程进行处理后再向 TiKV 发起请求:
- 先基于 region 进行分组,将相同的 region 的数据分到一个 groupMutations
- 再基于 batch_size 阈值,对 groupMutations 划分为多个 batchMutations,
- 最终每个 batch 的数据经由各自的 action 实现的 handleSingleBatch 函数向 TiKV 发送数据。
有如下四个 actions,对应着事务的不同过程:
1 | func (action actionPrewrite) handleSingleBatch(c *twoPhaseCommitter, bo *retry.Backoffer, batch batchMutations) error; |
如果 memBuffMutations 只有一个 region 的数据,那么就可以直接使用 1 phase commit 进行优化。
下面是分组分批提交的细节
doActionOnMutations
groupSortedMutationsByRegion
在 groupSortedMutationsByRegion,通过向 pd 查询每个 key 所属的region,直接对已排序的 key 进行分组,划分到不同的group中。
1 | // groupSortedMutationsByRegion separates keys into groups by their belonging Regions. |
preSplitRegion
如果一个 groupedMutations 的数据量过大,tikv-client 会先向 tikv-server 发起 split_region gRPC,请求这个 groupedMutations 对应的 region 分裂,并等待 region 分裂完成。这样避免单个 region 的写负载太重错误: “too much write workload”, 避免了不必要的重试
如果确实分裂了,那么基于 groupSortedMutationsByRegion 函数得到的 region 信息就过时了,需要重新执行一次 groupSortedMutationsByRegion 函数,再执行写入操作。

groupMutations
完整的 groupMutations 逻辑如下:
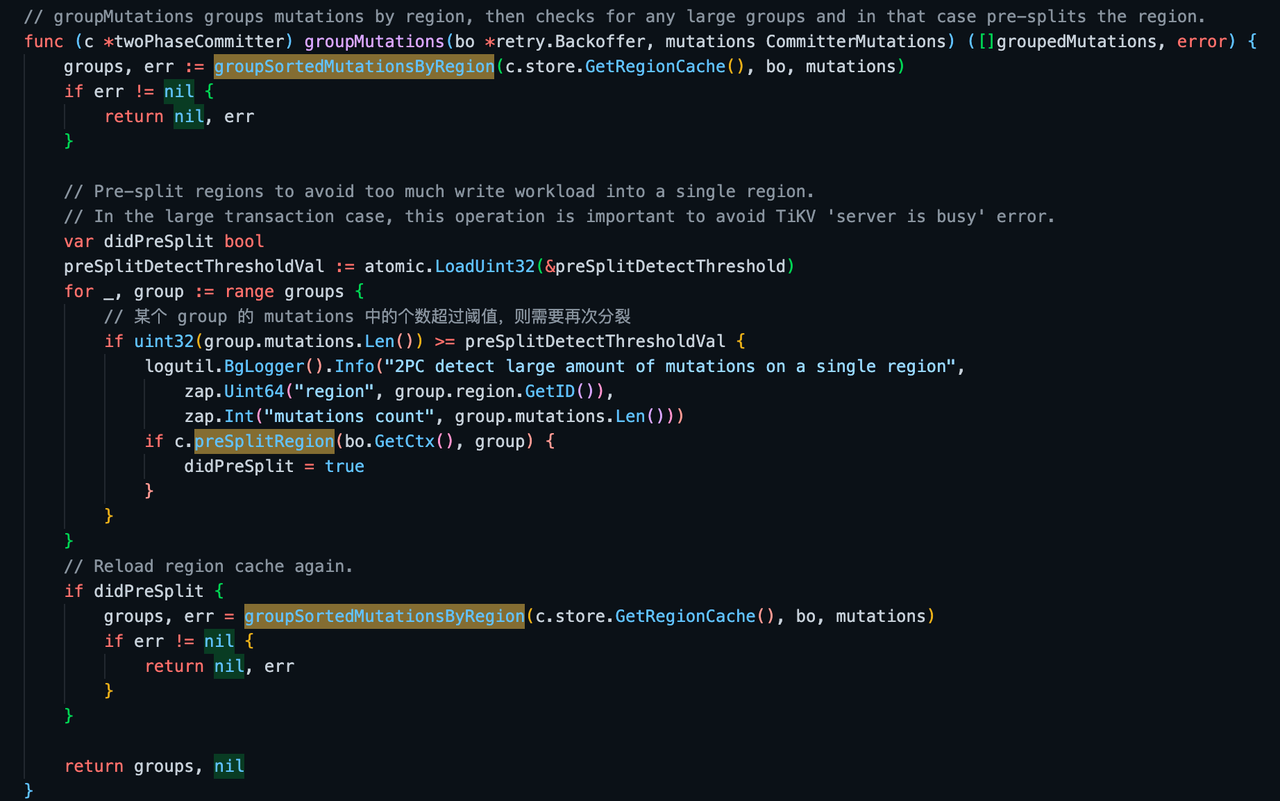
doActionOnGroupMutations
doActionOnGroupMutations 会对每个 group 的 mutations 做进一步的分批处理,最终将所有的 groupMutations 统一划分成多个 batchMutations,其中只有一个 Primary BatchMutations,其他的是 Secondary BatchMutations。写入的时先同步执行 Primary BatchMutations 中的数据,再异步执行 Secondary BatchMutations 中的数据。
batched 的定义如下
1 | type batched struct { |
batched::appendBatchMutationsBySize
对 groupMutations 进行分批是由 appendBatchMutationsBySize 函数实现:
- 对每个 groupMutations 进行划分成 batchMutations,每个 batchMutations 的大小限制在 16 * 1024 字节大小。
- 同时,在batch分组中,会寻找 groupMutations 中是否存在「主键」,如果存在则记录主键所属的 batch的在整个batches中的索引位置
1 | type batched struct { |
batched::setPrimary
分批结束后,使用 setPrimary 函数将 primaryIdx 对应 batchMutations 放到首位,方便后面先发送 Primary BatchMutations 中的数据。
1 | func (b *batched) setPrimary() bool { |
完整 doActionOnGroupMutations 的核心逻辑如下:
1 | func (c *twoPhaseCommitter) doActionOnGroupMutations(bo *Backoffer, action twoPhaseCommitAction, groups []groupedMutations) error { |
doActionOnBatches
内部调用的 handleSingleBatch,不同的 actions 实现不同,下面结合乐观事务和悲观事务进行讲解。
乐观事务
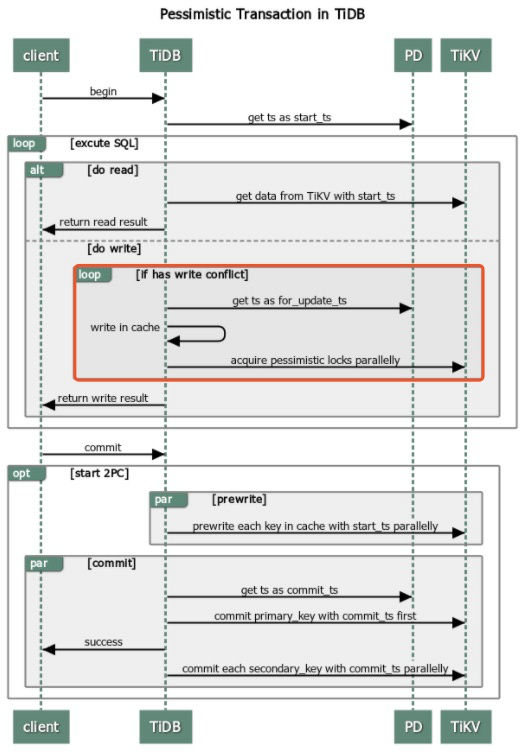
在 COMMIT 阶段,TiDB 开始两阶段提交:
- TiDB 并发地向所有涉及的 TiKV 发起 prewrite 请求。TiKV 收到 prewrite 数据后,检查数据版本信息是否存在冲突或已过期。符合条件的数据会被加锁,将锁信息写入 CF_LOCK,{key_start_ts},数据写入 CF_DAFAULT
- TiDB 收到所有 prewrite 响应且所有 prewrite 都成功。
- TiDB 向 PD 获取第二个全局唯一递增版本号,定义为本次事务的 commit_ts。
- TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交。TiKV 收到 commit 操作后,检查数据合法性,向 CF_WRITE中写入信息,并清理 prewrite 阶段留下的锁,即清理 CF_LOCK中的。
- TiDB 收到两阶段提交成功的信息。

actionPrewrite
TiKV-Client
TiDB 向 TiKV发送 Prewrite 请求,
- 遇到了 lock error, 则尝试 ResolveLock 去解决锁冲突, 然后重试;
- 如果遇到了regionError,说明之前获取的 region 信息错误,则需要重新调用 doActionONMutations 重新分组分批,重新尝试。
如果没有 keyError,并且 Primary BatchMutations. 则启动一个 tllManager,给 txn 的 primary lock续命,ttlManager 会定期的向 TiKV 发送txnHeartbeat, 更新 primary lock 的 ttl。
悲观事务
TiDB 在3.0版本引入了悲观事务,在两阶段提交之前增加了 Acquire Pessimistic Lock 获取悲观锁阶段,
- (同乐观锁)TiDB 收到来自客户端的 begin 请求,获取当前时间戳作为本事务的 StartTS。
- TiDB 收到来自客户端的更新数据的请求:TiDB 向 TiKV 发起加悲观锁请求,该锁持久化到 TiKV。
- (同乐观锁)客户端发起 commit,TiDB 开始执行与乐观锁一样的两阶段提交。
MvccTxn
TiKV 有三个 ColumnFamily(CF)保存事务信息:
- CF_LOCK:用于保存事务的锁信息,表示有事务正在写这个 key,key => lock_info
- CF_DEFAULT:用于保存 MVCC 数据,(user_key, start_ts) => value
- CF_WRITE :用于保存 Value 可见的版本控制,(key, commit_ts)=> write_info
这些数据经由MvccTxn类,写入 modifies,最终都会进入raft状态机,由leader节点同步给follower,超过半数节点确认后才会回应 client。
1 | impl MvccTxn { |
acquire_pessimistic_lock
TiKV 使用 acquire_pessimistic_lock 函数来获得每个 key 的锁,即 向 CF_LOCK 中写入当前 key 的锁信息,用来占位,等待 prewrite 阶段再向 CF_LOCK 和 CF_DEFAULT 中分别写入具体的 lock_info 和数据。
TiKV 需要先从 CF_LOCK 中检测是否已经存在该 key 的锁信息:
Yes: 此时就存在一些冲突了,需要解决这个冲突
- 如果 lock.ts != reader.start_ts:则说明不是同一个事务。即设当前事务是 T1,则在 T1 之前已经有个事务 T0 抢占了这个 key 的锁,而且 T0 尚未 commit,那么就向 client 返回 ErrorInner::KeyIsLocked 错误,client 接受到这个错误就会进行 ResolveLock 处理本次冲突。
- 如果 lock.lock_type != LockType::Pessimistic:则已存在的 T0 事务和 T1 不是同一个类型的事务,则直接返 ErrorInner::LockTypeNotMatch 错误信息。
如果上述两个 check 都通过了,则视为同一个事务 T0,此时会尝试更新 lock 的 for_update_ts 信息,然后根据 return_value、need_check_existence、need_old_value 等标志位来决定是否需要从 RocksDB 中读取数据返回给 client。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67pub fn acquire_pessimistic_lock<S: Snapshot>(
txn: &mut MvccTxn,
reader: &mut SnapshotReader<S>,
key: Key,
primary: &[u8],
should_not_exist: bool, // 针对插入操作,应该不存在
lock_ttl: u64,
for_update_ts: TimeStamp,
need_value: bool,
need_check_existence: bool,
min_commit_ts: TimeStamp,
need_old_value: bool,
) -> MvccResult<(Option<Value>, OldValue)> {
//... 检测 CF_LOCK 中是否有锁记录
if let Some(lock) = reader.load_lock(&key)? {
// CF_LOCK
if lock.ts != reader.start_ts {
return Err(ErrorInner::KeyIsLocked(lock.into_lock_info(key.into_raw()?)).into()); // lock
}
// 不是同一个事务
// 上一个必须也是 LockType::Pessimistic
if lock.lock_type != LockType::Pessimistic {
return Err(ErrorInner::LockTypeNotMatch {
start_ts: reader.start_ts,
key: key.into_raw()?,
pessimistic: false,
}
.into());
}
if need_load_value {
val = reader.get(&key, for_update_ts)?;
} else if need_check_existence {
val = reader.get_write(&key, for_update_ts)?.map(|_| vec![]);
}
// Pervious write is not loaded.
let (prev_write_loaded, prev_write) = (false, None);
let old_value = load_old_value(
need_old_value,
need_load_value,
val.as_ref(),
reader,
&key,
for_update_ts,
prev_write_loaded,
prev_write,
)?;
// Overwrite the lock with small for_update_ts
if for_update_ts > lock.for_update_ts {
let lock = PessimisticLock {
primary: primary.into(),
start_ts: reader.start_ts,
ttl: lock_ttl,
for_update_ts,
min_commit_ts,
};
txn.put_pessimistic_lock(key, lock); // 更新 lock 信息
} else {
MVCC_DUPLICATE_CMD_COUNTER_VEC
.acquire_pessimistic_lock
.inc();
}
// 视为同一个事务的重复请求
return Ok((ret_val(need_value, need_check_existence, val), old_value));
}
//...
}No: 如果 CF_LOCK 中没有 key 的锁信息,即 reader.load_lock(&key) 返回的是 None,此时仍需要去 CF_WRTIE 中检测是否有对应的写记录,进一步判断当前事务 T1 的状态。
因为当前事务 T1 可能被其他事务清除了,或者 TTL 过期。当删除事务时会删除 Key 在 CF_LOCK、CF_DEFAULT 中的记录,在 CF_WRITE 中留下一条 Rollback 记录。
reader.seek_write(&key, TimeStamp::max()) 寻找的是 key 在 CF_WRITE 中最新的写入记录:
如果返回不为 None 且假设为 Some(commit_ts, write),则有两种可能:
- 上次 committed 记录:正常情况下, T0 的 commit_ts > T1 的 for_update_ts,如果违背了,则产生了一次写冲突
- 上次 rollback 记录
如果 commit_ts == reader.start_ts 并且满足 write.write_type == WriteType::Rollback || write.has_overlapped_rollback,那么说明当前事务 T1 已经被删除了,只留下一条 rollback 记录,不能再获取锁了,则返回 ErrorInner::PessimisticLockRolledBack 错误给 client。
如果 commit_ts > reader.start_ts,则说明当前事务已经过期,去检测 reader.start_ts 上一个事务的的状态,如果也是 rollback,则也向 client 回复 ErrorInner::PessimisticLockRolledBack 错误。
返回 None,则表示 CF_WRITE 中不存在 key 的记录,那么当前事物 T1 可以顺利获取Key的锁,则会向 CF_LOCK 中插入当前 key 的 lock 信息,表示获得该 key 的锁成功了。
这部分代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74pub fn acquire_pessimistic_lock<S: Snapshot>( /*..ingore params.*/ ) -> MvccResult<(Option<Value>, OldValue)> {
/// ...
/// 当前没有 lock,即没有别的任务在写
let (prev_write_loaded, mut prev_write) = (true, None);
// 进一步在 CF_WRITE 中寻找
if let Some((commit_ts, write)) = reader.seek_write(&key, TimeStamp::max())? {
// Find a previous write.
if need_old_value {
prev_write = Some(write.clone());
}
// 上个提交的版本,比当前事务的时间戳大
// 产生了写冲突
if commit_ts > for_update_ts {
return Err(ErrorInner::WriteConflict {
start_ts: reader.start_ts,
conflict_start_ts: write.start_ts,
conflict_commit_ts: commit_ts,
key: key.into_raw()?,
primary: primary.to_vec(),
}
.into());
}
// Handle rollback.
// The rollback information may come from either a Rollback record or a record with
// `has_overlapped_rollback` flag.
if commit_ts == reader.start_ts
&& (write.write_type == WriteType::Rollback || write.has_overlapped_rollback)
{
assert!(write.has_overlapped_rollback || write.start_ts == commit_ts);
return Err(ErrorInner::PessimisticLockRolledBack {
start_ts: reader.start_ts,
key: key.into_raw()?,
}
.into());
}
// If `commit_ts` we seek is already before `start_ts`, the rollback must not exist.
// 可能是一个反复重试的
if commit_ts > reader.start_ts {
if let Some((older_commit_ts, older_write)) =
reader.seek_write(&key, reader.start_ts)?
{
if older_commit_ts == reader.start_ts
&& (older_write.write_type == WriteType::Rollback || older_write.has_overlapped_rollback)
{
return Err(ErrorInner::PessimisticLockRolledBack {
start_ts: reader.start_ts,
key: key.into_raw()?,
}
.into());
}
}
}
//...
}
let lock = PessimisticLock {
primary: primary.into(),
start_ts: reader.start_ts,
ttl: lock_ttl,
for_update_ts,
min_commit_ts,
};
// 写入的是 lock 信息,此 lock 信息稍后会统一写入存储层
txn.put_pessimistic_lock(key, lock);
// TODO don't we need to commit the modifies in txn?
Ok((ret_val(need_value, need_check_existence, val), old_value))
}
prewrite
prewrite 目的是在 CF_LOCK 和 CF_DEFAULT 写入记录,如果成功,则客户端能顺利发起 Commit 请求。当然,如果是悲观事务,则在 acquire_pessimistic_lock 阶段就已经在 CF_LOCK 中写入记录,那么在 prewrite 阶段就肯定能成功。
因此,在 prewrite 函数中,先尝试从 CF_LOCK 中读取 lock 的信息:
- 有 lock,则需要在 PrewriteMutation::check_lock 函数中进一步 check;
- 没有 lock,但是当前又是悲观事务,则需要在 CF_LOCK 中加上 lock_info:这是TiKV 在v6.1引入 pipeline write 设计可能出现的 corner case
- 返回None,即乐观事务
代码如下:
1 | pub fn prewrite<S: Snapshot>( |
PrewriteMutation::check_lock
check_lock 的逻辑和 acquire_pessimistic_lock 有点类似,仍假设当前事务为 T1,之前的事务为 T0
进入这个函数已经确定 CF_LOCK 中存在锁:
- 若 lock.ts != self.txn_props.start_ts,则说明已经存在事务 T0:
- 若 T1 是悲观事务,则之前在 acquire_pessimistc_lock 阶段写入的 lock 不存在了,可能被清除了,则返回 ErrorInner::PessimisticLockNotFound 错误;
- 否则 T1 即乐观事务,由于乐观锁只是在 prewrite 阶段尝试上锁,如果相同key上的锁已经被其他事务 T0 占据,则返回 ErrorInner::KeyIsLocked, 则让客户端发起 ResolveLock 来解决这个锁冲突
- 如果 lock.ts == start_ts, 则再检测 lock.lock_type 是否一致:
- 如果不一致,则返回 ErrorInner::LockTypeNotMatch 错位。
- 如果一致:
- 悲观事务:更新 lock_ttl、min_commit_ts
- 乐观事务:那么当前这次 prewrite 就是个重复指令,无需更新任何数,幂等操作
1 | /// Check whether the current key is locked at any timestamp. |
PrewriteMutation::write_lock
上述 check 都通过了,则将 CF_LOCK 和 CF_DEFAULT 中写入数据,流程如下:
如果 sizoef(value) < 256,即 is_short_value(&value) 为 true,则直接会有个优化,直接将 value 写入到 CF_LOCK 中,否则value需要写入 CF_DEFAULT 中;
如果开启了 async_commit,则会在 key 中记录所有的 secondaries key,方便后续查询所有 secondaries 的状态。
如果开启了 async_commit,这里需要基于所有的 secondaries 计算 final_min_commit_ts,返回给 tikv-client,让 client 使用这个 final_min_commit_ts 来作为进行异步 commit 的时间戳
最后将向 txn 中写入 lock 信息
因此, prewtite 阶段成功后,Rocksdb 中就记录了 锁信息和真正的数据,就等待 commit 中的 write 信息了。
1 | fn write_lock(self, lock_status: LockStatus, txn: &mut MvccTxn) -> Result<TimeStamp> { |
Commit
第一阶段 prewrite 成功,TiDB 向 PD 再获取一个单调递增的时间戳 commit_ts 用于第二段提交,在 CF_WRITE 中写入提交信息,并清除第一阶段prewrite中写入的 lock 信息。
1 | pub fn commit<S: Snapshot>( |