WriteThread 如何使用 Pipeline 提升写入吞吐,降低延迟
在前面几篇讲解了从 WriteBatch 的内部序列化流程 和 WriteThread 如何控制并发写入的基本流程,本文进一步讲解 WriteThread 如何使用 PipelinedWrite 来提升写吞吐,其中和前文相似的逻辑不再细说。
通过设置选项 DBOptions::enable_pipelined_write = true 来开启,开启后整个db的 WriteThread 都是通过 PipelinedWrite 方式控制写入流程。
1 | if (immutable_db_options_.enable_pipelined_write) { |
WAL: Pipelined Write
在之前的 WriteThread 写入控制流程中, 是依次有序地将数据写入 WAL 和 MemTable,那么如何使得 WAL 和 MemTable 的写入操作并行起来?
在多个 writers 并发写入同一个 RocksdB 实例时,只要前一个 writer_group0 将数据写入 WAL 了,那么下一个 writer_group1 就不必等待 writer_group0 完成 MemTable 写入流程,writer_group1 就可以开始自己的 WAL 写入流程: 因此 writer_group0 的 MemTable 写流程和 writer_group1 的 WAL 写流程就可以并行起来。
上述就是 PipelinedWrite 的核心思想。因此 PipelinedWrite 需要开启 WAL,来保证 writer_group0 写入 WAL 的数据不会丢。
MemTable: Concurrent Write
已经写入 WAL 的数据不会丢,那么是否可以在写入 MemTable 时,允许多个 writers 并发地写 MemTable,而不是原先由 leader-writer 来完成 memtable_write_group 的写入?
选项 DBOptions::allow_concurrent_memtable_write 默认值为 true,即默认支持并发写入 MemTable,但实际上当前只有基于 skiplist 实现的 MemTable 才支持这一特性( SkipListRep 也是 MemTable 的默认实现)。
因此,在写路径使用 PipelineWrite 实现时,实际上就有了两种优化:
- WriteGroup 之间可以 Pipeline
- MemTable 可以并发写入
从实现角度,可以粗略地将有 PipelinedWriteImpl 函数划分成三个阶段(任务):
T1:完成当前 write_group0 的 WAL 写入流程,
T2:通知 write_group1 开启 WAL 写入流程,即 write_group1 无需等待 write_group0 完成 MemTable 写入流程才开启自己的 WAL 写入流程;
T3:write_group0 的 WAL 写入流程完成后,需要启动 write_group0 的并发写 MemTable 流程。
实际上,在 T3 阶段可能会携带其他 write_group 的 writers 一起进入 T3 阶段,来提升性能,详情见后文。
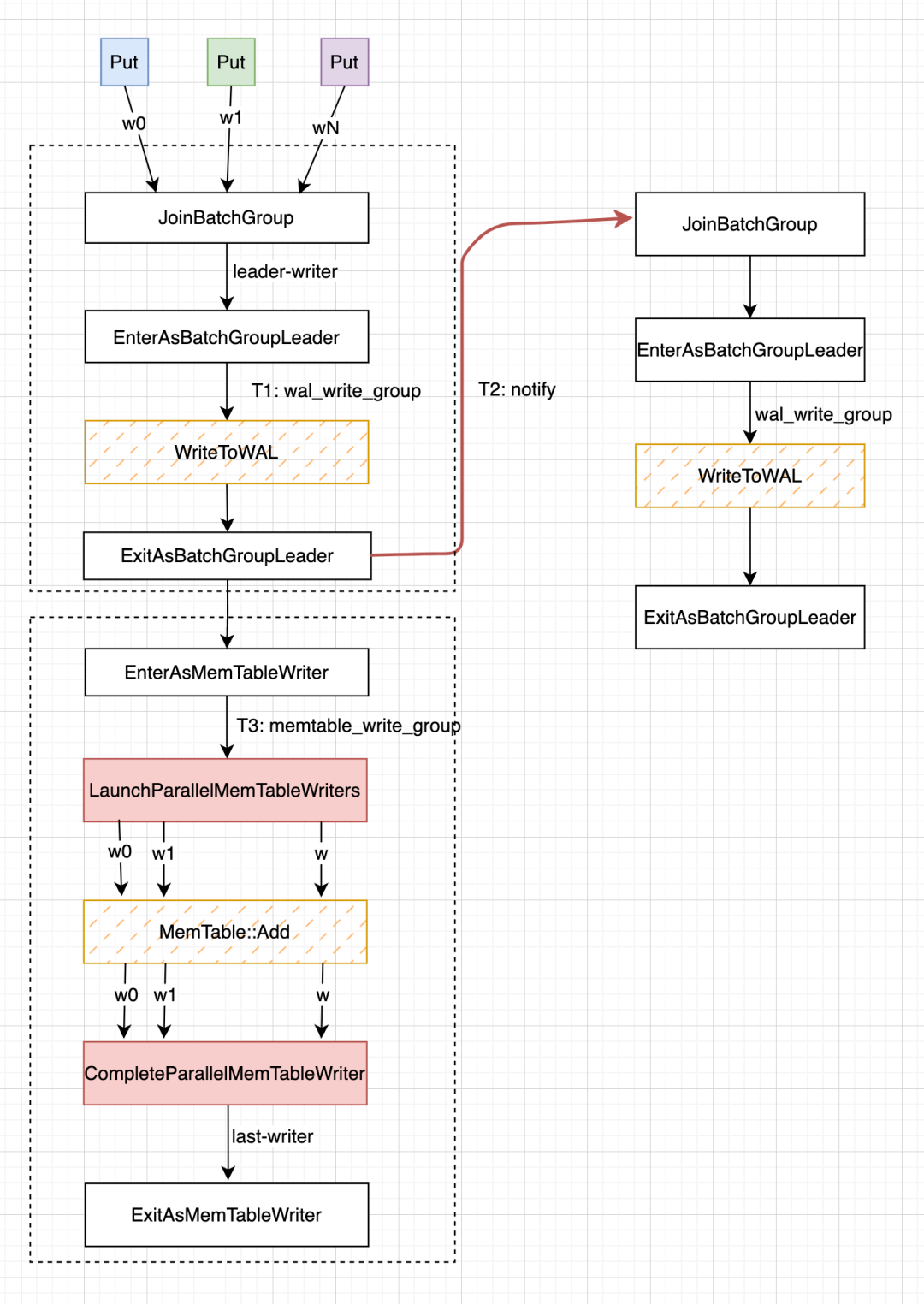
由于后两个任务都需要等待第一个任务完成,因此三个任务的分界点就可以设置在 WrriteThread::ExitAsBatchGroupLeader 函数中: T1 在写 WAL 期间需要整个 RocksDB 只有一个 leader-writer,在 T1 任务结束后就可以不再担任 leader 角色。此时有两件事需要做 1) 挑选出下一个 WriteGroup 中的 leader-writer,让 T2 任务可以 pipeline 执行;2) 开启当前 WriteGroup 并发写入 MemTable 流程。
整个设计如下图:
T1
T1 任务的流程和 WriteThread 如何控制并发写入流程 的基本一致,都需要经过 JoinBatchGroup -> EnterAsBatchGroupLeader -> ExitAsBatchGroupLeader, 只是将原来 leader-writer 作用范围(WriteToWAL 和 MemTable::Add) 范围缩小到了仅有 WALs。
因此,只有当 JoinBatchGroup 函数返回的 writer 是 leader-writer 时才会进入 WAL 写流程,而且当前 write_group0 的其他 writers 和后续 write_group1 等都会阻塞在 JoinBatchGroupl 函数处。
具体的阻塞逻辑可以参考 WriteThread 如何自适应优化线程同步。PipelineWriteImpl 的函数入口代码如下:
1 | WriteThread::Writer w(write_options, my_batch, callback, log_ref, |
因此,PipelinedWrite 如何关联前后 writer_group 的核心就在 ExitAsBatchGroupLeader 函数中了。
ExitAsBatchGroupLeader
在前文 WriteThread 如何控制并发写入流程 已经详细讲解了 ExitAsBatchGroupLeader 函数在 enable_pipelined_write == false 时的执行流程,下面来讲另一个分支。主要有两个任务:
T2:选出下一个 write_group1 中的 leader-writer,使其也进入写 WAL 流程
T3:由
CompleteLeader和CompleteFollower函数提前将不用写入 MemTable 的 writrs 从 write_group0 链表中删除。将write_group0中剩余的 writers 移动到newest_memtable_writer_指向的链表。只有 leader-memtable-writer 才能开启并发写 MemTable 的流程,
w->state状态会变成STATE_MEMTABLE_WRITER_LEADER。如果此时多个 write_group(wg0,wg1)的 leader-writer 都想变成 leader-memtable-writer,假设最终 wg0->leader 成功,则新的 memtable_write_group 实际上会包含 (wg0, wg1),并且 wg1->link_older = wg0 的方式串联起来。
接着,leader-memtable-writer 通过
LaunchParallelMemTableWriters函数来启动memtable_write_group并发写 MemTables 的流程,follower-writer 才会解除阻塞等待, 进入 MemTable::Add 写入流程。
整体代码如下。
1 | void WriteThread::ExitAsBatchGroupLeader(WriteGroup& write_group, |
CompleteFollower
WriteThread 是逆序从 [last_writer, leader) 来删除不需要写入 MemTable 的 writers-follower 节点。这个 write_group 的 writers list 首尾节点是 leader 和 last_writer。 CompleteFollower 删除的都是 followers 节点,因此在删除时需要注意下是不是尾部节点 last_writer 即可。
这里只需要将 w 从 write_group 中剔除即可,并不需要 delete w,而是将 w->state 状态设置为 STATE_COMPLETED。这是因为 w 这份资源由 w 所属的线程去释放,将其状态更改为 STATE_COMPLETED 后,w 所属的线程就会解除阻塞,去释放这份资源,回到应用层。
CompleteLeader 逻辑也类似。
1 | void WriteThread::CompleteFollower(Writer* w, WriteGroup& write_group) { |
LinkGroup
LinkGroup 函数的作用是将当前 write_group0 中需要向 MemTable 写数据的 writers 转移到 newest_memtable_writer_ 中来,并且保持 write_group0 中的顺序。
先断开
(leader, last_writer]区间所有的w->link_newer/prev指针(leader->link_newer 已经是 NULL)。这是因为LinkGroup可能会将多个 WriteGroup 的 writers 串到一个newest_memtable_writer_指针中,后续需要重新建立 prev 指针。通过
compare_exchange_weak尝试让newest_memtable_writer_指向last_writer。多个并发的 WriteGroup 通过 link_older 指针串联起来。因此,在
ExitAsBatchGroupLeader函数末尾会有个AwaitState(leader, state)代码,用于阻塞那些被串在 memtable_write_group 中的 follower-memtable-writers,等待 leader-memtable-writer 调用LaunchParallelMemTableWriters函数才能解除阻塞。
原理和 LinkOne 函数差不多,代码如下:
1 | bool WriteThread::LinkGroup(WriteGroup& write_group, |
T2
T1 在 ExitAsBatchGroupLeader 函数中已经选出 write_group1 的 leader-writer, 因此不会等待 write_group0 完成,T2 就会直接启动。重复write_group0 的 T1 流程。
T3
write_group0 执行完 T1 任务后就进入 T3 阶段,准备并发写 MemTables 操作。这个阶段的写流程如下:
leader-memtable-writer 会通过 EnterAsMemTableWriter 获取 memtable_write_group,
如果 memtable_write_group 的 writers 数量大于 1 则调用
LaunchParallelMemTableWriters函数启动所有的 writers 进入 MemTable::Add 阶段。否则,当前 leader-memtable-writer 就直接写 MemTable。
写 MemTable 的操作是由
WriteBatchInternal::InsertInto函数完成。
而 follower-memtable-writers 会一直阻塞等待在两个的地方:
- 当前 write_group0 的 followers 会阻塞在 PipelineWriteImpl 函数开始的 JoinBatchGroup 处
- 其他 write_group1 的 followers 会阻塞在 ExitAsBatchGroupLeader 函数末尾的 AwaitState 处
因此,当 leader-memtable-writer 调用 LaunchParallelMemTableWriters 函数,则会解除上述两处阻塞状态的 writers,进入 T3 阶段。
1 | WriteThread::WriteGroup memtable_write_group; |
EnterAsMemTableWriter
EnterAsMemTableWriter 函数和 EnterAsBatchGroupLeader 工作逻辑类似,从 newest_memtable_writer_ 中取出memtable-writers,组成一个由 [leader, last_writer] 组成的 memtable_write_group。
1 | void WriteThread::EnterAsMemTableWriter(Writer* leader, |
LaunchParallelMemTableWriters
LaunchParallelMemTableWriters 函数即遍历 memtable_write_group 中所有的 writers,将其 w->state 设置为 STATE_PARALLEL_MEMTABLE_WRITER 来解除阻塞。
1 | void WriteThread::LaunchParallelMemTableWriters(WriteGroup* memtable_write_group) { |
CompleteParallelMemTableWriter
所有的 w->state 都在 LaunchParallelMemTableWriters 函数中被更改 STATE_PARALLEL_MEMTABLE_WRITER,此时已经没有主从 writers 的概念。
每个 writer 都并发地调用 WriteBatchInternal::InsertInto 函数向 MemTable 写数据。每个 writer 写完 MemTable,都会调用一次 CompleteParallelMemTableWriter 来检测自己是不是 memtable_write_group 中最后一个完成写 MemTable 的 writer。最后一个 memtable-writers 在 ExitAsMemTableWriter 函数中做善后工作。
1 | if (w.state == WriteThread::STATE_PARALLEL_MEMTABLE_WRITER) { |
每次 memtable-writer 写完 MemTable,都会进入 CompleteParallelMemTableWriter 将 memtable_write_group->running 减 1: 如果不是最后一个 memtable-writer,则阻塞等待最后一个 memtable-writer 完成后在 ExitAsMemTableWriter 函数中将所有的 writers 状态更改为 STATE_COMPLETED,则本次并发写 MemTable 操作结束。
1 | bool WriteThread::CompleteParallelMemTableWriter(Writer* w) { |
ExitAsMemTableWriter
ExitAsMemTableWriter 函数和 ExitAsBatchGroupLeader 函数类似,主要有两个作用:
选出下一轮 memtable_write_group1 的的 leader-memtable-writer,将其 state 设置为
STATE_MEMTABLE_WRITER_LEADER,使下一轮 memtable_write_group1 能尽快进入 T3 阶段;将本轮 memtable_write_group0 的所有 memtable-writers 的状态更改为
STATE_COMPLETED,解除阻塞在CompleteParallelMemTableWriter函数处阻塞的 writers,让他们释放资源返回应用层。这里需要让 leader-memtable-writer 最后一个退出,因为它拥有 memtable_write_group 所有权:如果它不是最后一个释放,会造成
ExitAsMemTableWriter函数在执行过程中 coredump。
这部分代码如下。
1 | void WriteThread::ExitAsMemTableWriter(Writer* /*self*/, |