MemTable、WAL、ColumnFamily 简述
Overview
尽管 rocksdb wiki 中 rocksdb-overview 已经描述了,本文以自己的理解作为一个补充。
如图 rocksdb 的总体架构图中主要由 MemTable, WAL 和 sstfile 三个基本组件组成,本文主要阐述下他们之间的协作关系。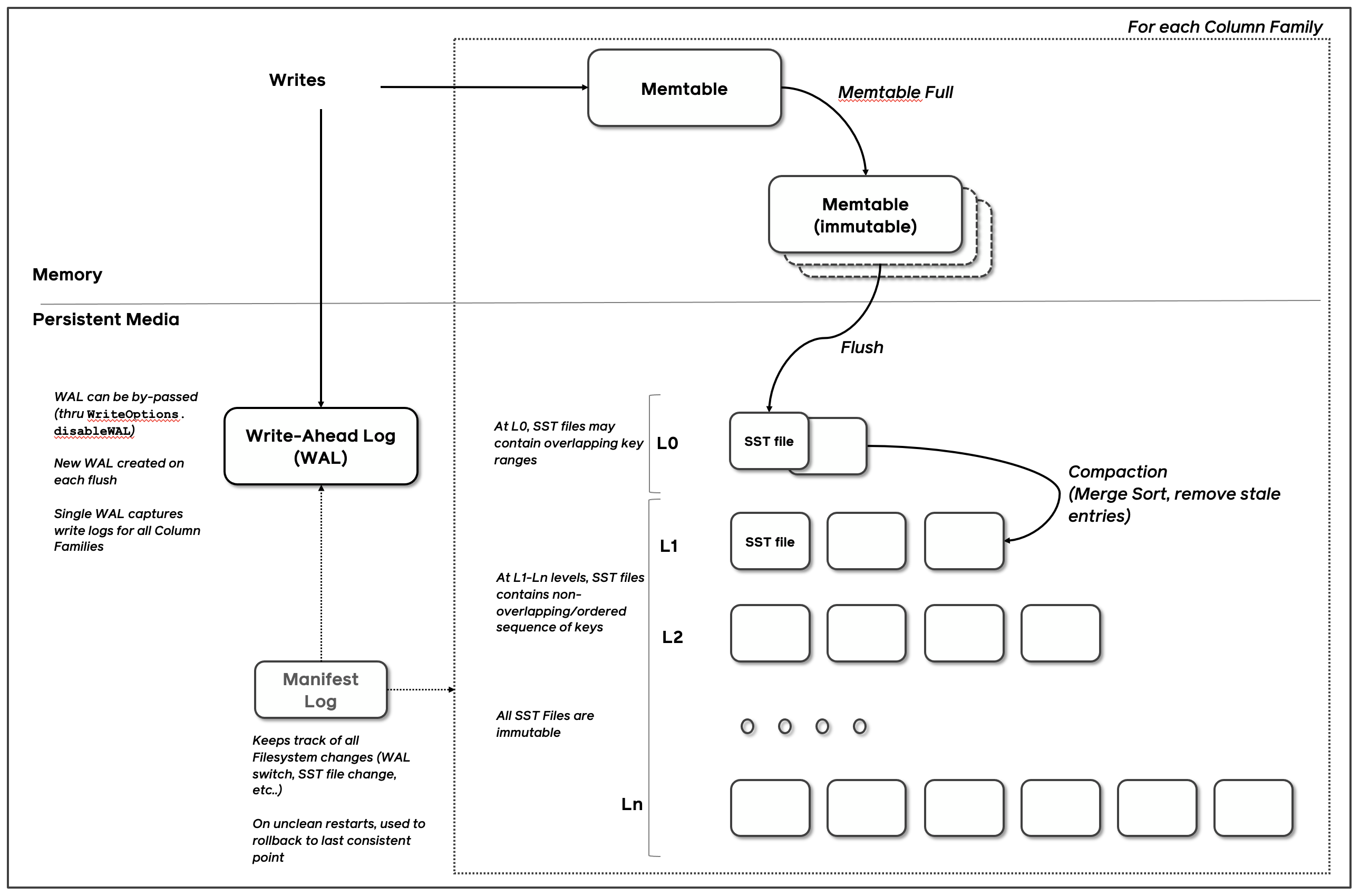
MemTable
写入的kv数据会先写入 WriteBatch, 在经过 WriteBatchInternal 封装后写入 MemTable。
MemTable 是在读写路径中共享,这样可以减少读写路径中和磁盘交互的频次。但由于 MemTable 是个内存结构,为了防止各种故障导致 MemTable 中数据丢失,进而引入 WAL (Write Ahead Log),即每次写入的数据,会先写入 WAL,成功后再写入 MemTable,如果 MemTable 中的数据丢失则从 WAL 中恢复。
正常情况下,写入的数据会持续写入 MemTable,直到 MemTable 的大小超过阈值,则会变成只具有只读属性的 ImutableMemTable, 同时创建新的 MemTable 接受后续的写入。等待后台线程 Pickup 合适的 ImmutableMemTables,将其 Flush 到 $Level_0$ 中,那么选中的 ImmutableMemTables 对应的 WALs 也可以删除了。
这里为什么用了 Pickup 这个说法?在 RocksDB-3.0 引入 cf(ColumnFamily) 设计,每个 cf 都有一个自己的 MemTable,但是所有的 cfs 共享一个 WAL:当向其中一个 cf 写入大量数据会导致它的 MemTable full 并转为 ImmtableMemTable。此时能直接删除当前 WAL 吗,由于WAL 可能仍保存着其他 cfs 的 MemTable 数据,这就涉及到 WAL 生命周期的问题。因此在删除 WALs 时,需要挑选出 WALs 生命周期结束的才能删除。
案例
TiKV 原本的架构是一个 TiKV-Server 上的所有 regions 共享两个 RocksDB 实例: raft-rocksdb 用于存放 raft log,kv-rocksdb 用于存放状态机数据,kv-rocksdb 实例有三个 column family,
- 事务 T1 在 prewrite 阶段写入 MemTable 的 lock 信息,在事务 T1 commit 阶段之前可能有其他热点 regions 写入大量数据导致 Flush MemTable,进而导致事务 T1 commit 阶段原本可以在 MemTable 中就可以查询到 lock 信息,现在需要去 sst 文件中查询,无疑增加了成本。
- 那么我们是否可以通过每个 region 一个 cf 来实现 region 的隔离?
显然也是不行,因为 cf 只是逻辑上的隔离,所有的 cf 仍共享一个 WAL:如果上万个 regions 对应上万个 cfs,如果会造成很多 WALs 生命周期无法结束、得不到释放,势必生成占用大量资源。
3. 每个 region 一个 RocksDB 实例
在 Release-6.6 提出 Partitioned-TiKV 架构,即每个 region 分配一个 rocksdb 实例,从物理层上实现 region 隔离,这样原本一个 region 只能存储 64M 的存储,现在可以存储10G+的数据,减少了写入过程 region-leader 分裂的频次。
Question: 但是也有其他问题,比如 每个 region 一个 rocksdb,是否会因为 MemTable 导致占用的内存增加?尤其本来 TiKV 对硬件要求就很高,如此硬件成本是否会更高,以及内部 region 合并时 两个不同 RocksDB 实例的 regions 数据如何合并。不过由于 tikv region 本身就是按照 kv-range 划分的,不存在重复,合并可能主要需要修改元数据信息。
这个设计可以参考: partitioned-raft-kv
SST
Rocksdb 引擎是个 LSM (Log Structured Merge) Tree, 其中 $level_0$ ~ $level_N$ 都由 sst(Sorted String Table) files 组成。
sstfile 是已经将 kv 数据有序存储在磁盘上,因此和 sstfile 有关的问题不再是数据有没有可能丢失,而是如何减少 LSM Tree 中不同 level 的 sstfiles 中存储的冗余数据。这种方式即 compaction。
- $Level_0$ 存储最新的数据, $Level_N$ 存储最旧的数据。
- $Level_0$ 中的 sstfiles 可能会有重复,$Level_1$ ~ $Level_N$ 中的数据不重复
当 Compaction 方式是 Level Compaction 时:
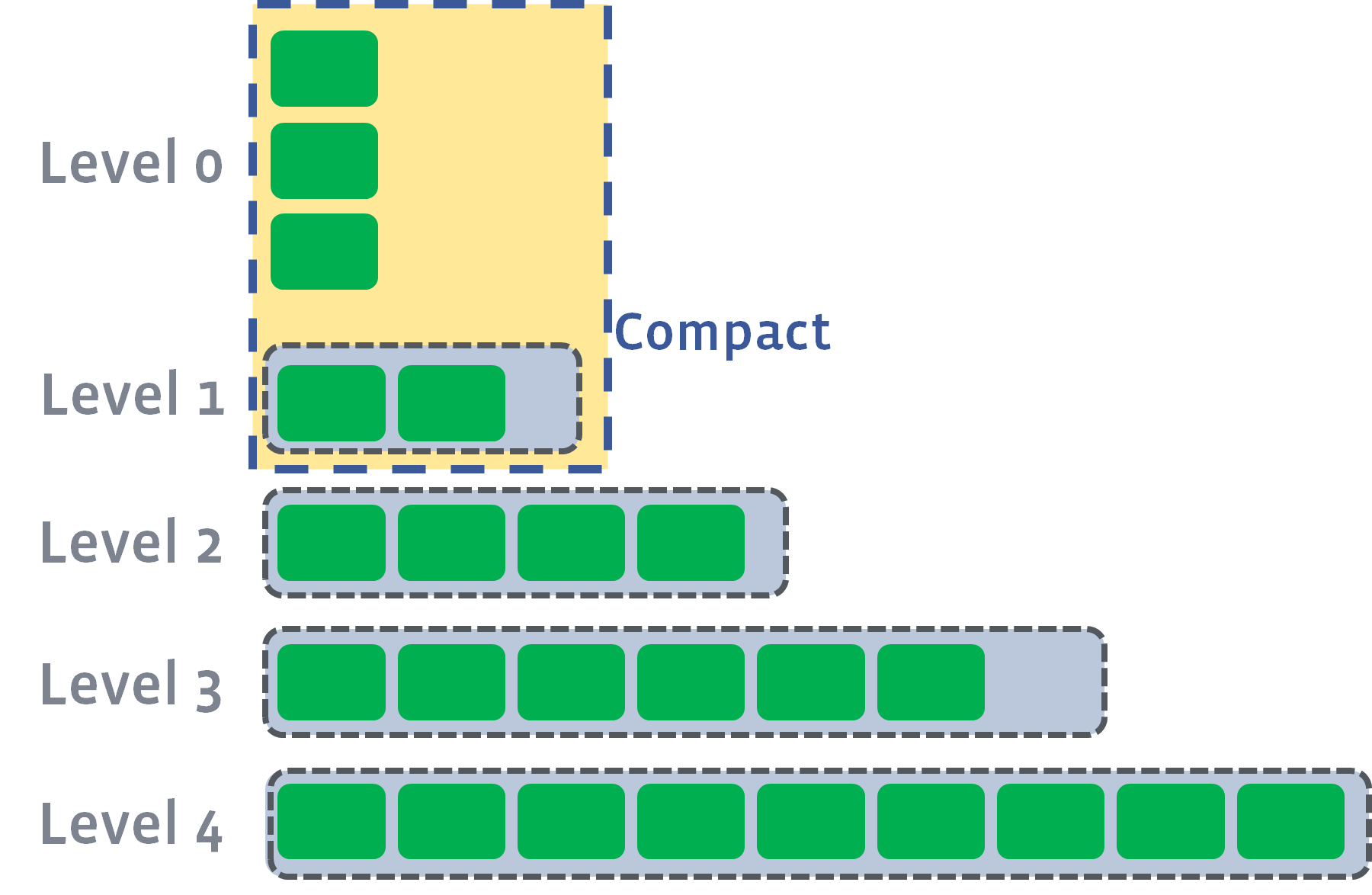
$level_0$: 当 MemTable 中的数据 Flush 到 $Level_0$ 时,会导致 $Level_0$ 存在重复的 kv range。当 $Level_0$ 的文件数量达到阈值
$Level_0$_file_num_compaction_trigger,$Level_0$ 会被合并到会和 $Level_1$,并保持使得 $Level_1$ 层的 sstfiles 仍然有序且无重复。如图是 $level_0$ 的 compaction 前后过程:
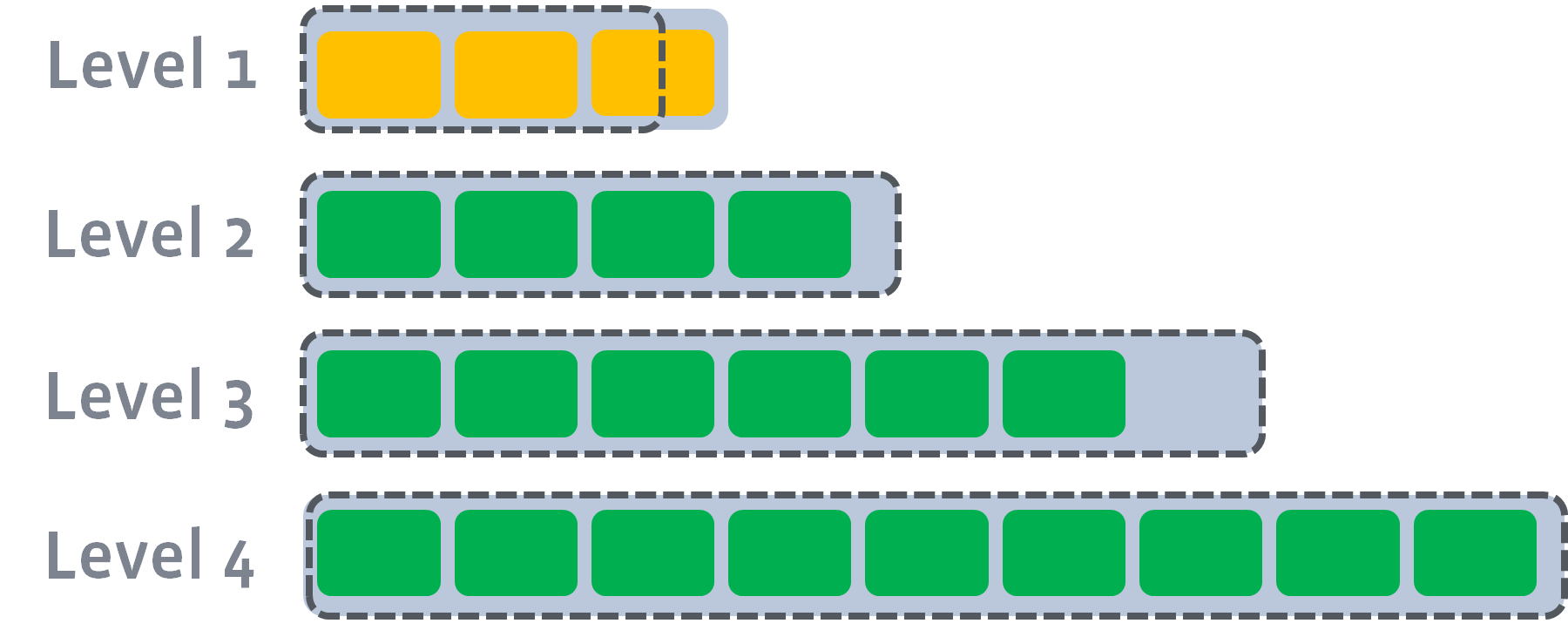
当 $$Level_1$$ 的数据量越来越大,会触发 $Level_1$(inpit-level)层和 $level_2$ (output-level)层的 compaction。
如图是 $level_1$ 的 compaction 前后过程:
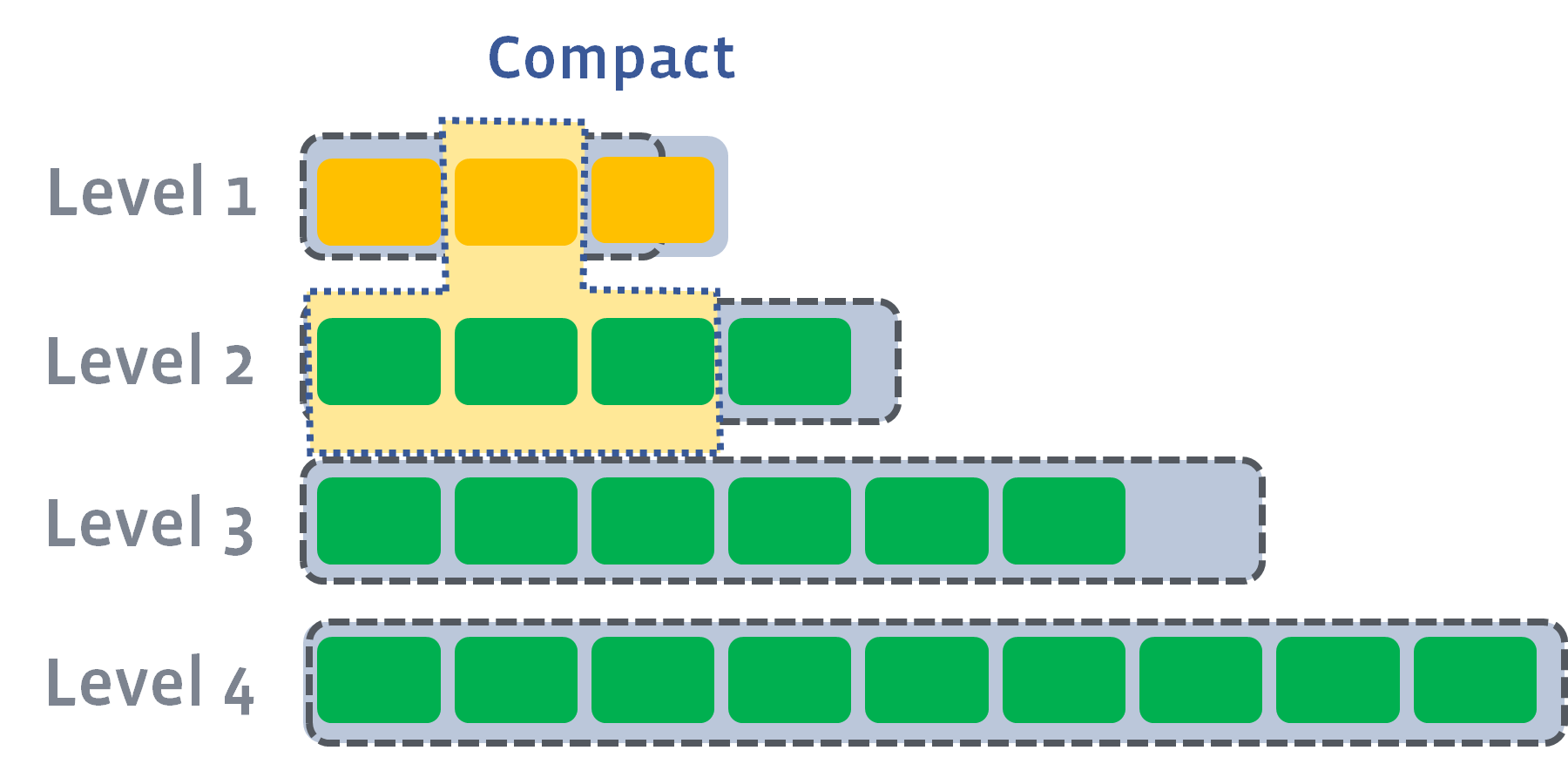

以此类推到 LSM 最底层。
这里面需要研究的细节:
- input/output level 中的哪些 sstfiles 进行 compaction
- 如何选择合适的 compaction 方式,平衡读写放大
- 当 value 较大,进行 kv 分离来降低写方大问题
由于现在新型的数据库的存储引擎基本都是以 LSM Tree 为蓝本, compaction 对内存和磁盘的影响就显得愈发重要,几乎都会借鉴 RocksDB 的设计。因此,在学习 RocksDB 时,compaction 是不可或缺的一点。
ColumnFamily
上面已经简述了 cf,它在逻辑上将 RocksDB 划分为多个 cf,每个 cf 类似一个关系数据库中的分区表的概念。
如图,cf 的实体是 class ColumnFamilyData,一个 RocksDB 实例可以有多个 cfs,都保存在 ColumnFamilySet 对象中。一个 cf 中要记录三大部分:
version: 表征的是 lsm tree 的 $Level_0$ - $Level_N$ 信息imm: 表征的是只读的 MemTable,不再接受写入的 MemTable;mm: 当前最新的 MemTable,接受读写
同样这里也存在version、imm 生命周期的问题,因为每次 flush/comapction,都会对 imm/version 产生影响,为了追踪生命周期,
MemTableList对象 imm 中有个MemTableListVersion对象,并有 Ref()/Unref() 函数来追踪生命周期;Version对象 version 也有 Ref()/Unref() 函数来追踪生命周期;
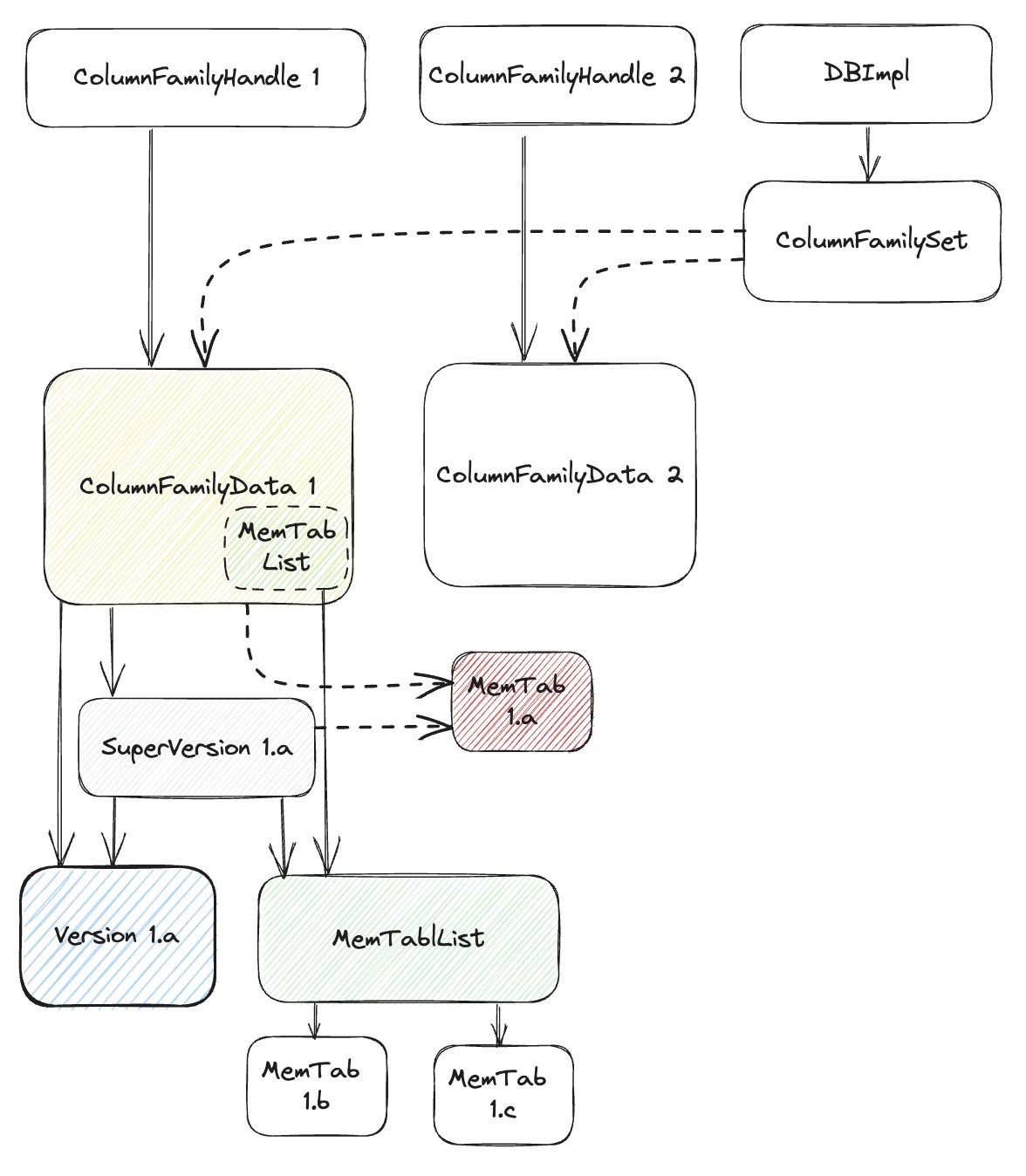
因此,关于 cf 也好理解,在分析这块的时候可以多关注下 WALs、Version 等生命周期的起始。
Get/MultiGet
读取路径会比较复杂,主要是将 mm/imm、sstfile 数据有序合并起来再取最新的数据输出,相关的三个迭代器 MergingIterator,CompactionIterator、RangeTomeStoneIterator 放在后续慢慢再讲解。这一部分还有一点就是利用 C++20 的协程实现异步IO来提取读取性能。